
通常のデータポイント
最終更新日: 28 年 2021 月 XNUMX 日概要
データポイントは、監視中に収集されるデータの一部です。 すべてのデータソース定義には、収集および保存する情報と、そのデータを収集、処理、および潜在的にアラートする方法を定義する、少なくともXNUMXつの構成済みデータポイントが必要です。 LogicMonitorは、通常のデータポイントと複雑なデータポイントのXNUMX種類のデータポイントを定義します。
通常のデータポイントは、収集された生の出力から直接抽出できる、監視するデータを表します。 一方、複雑なデータポイントは、保存する前に、生の出力で利用できないデータを使用して(たとえば、スクリプトや式を使用して)何らかの方法で処理する必要があるデータを表します。 複雑なデータポイントの詳細については、を参照してください。 複雑なデータポイント.
通常のデータポイントは、で概説されているように、データソース定義から構成されます。 データポイントの概要。 このサポート記事では、通常のデータポイントを構成するさまざまな構成について詳しく説明します。
通常のデータポイントメトリックタイプ
データソース定義から通常のデータポイントを構成する場合、ゲージ、カウンター、または派生のXNUMXつのメトリックタイプのいずれかを割り当てることができます。
ゲージメトリックタイプ
ゲージメトリックタイプは、データポイントのレポート値を直接保存します。 たとえば、生の値が90のデータは90として保存されます。
カウンターメトリックタイプ
カウンターメトリックタイプは、収集された値を発生率で解釈し、データポイントの120秒あたりの率としてデータを格納します。 たとえば、インターフェイスカウンタが600秒ごとにサンプリングされ、それぞれ1800、2400、3600、10の値を報告する場合、結果として保存される値は1800 =((600-120)/ 5)、2400 =((1800- 120)/ 10)および3600 =((2400-120)/ XNUMX)。
カウンターはカウンターラップを説明します。 たとえば、4294967290つのデータサンプルが6で、12秒後に発生する次のデータサンプルが32の場合、カウンターは値0を格納し、XNUMXビット制限でラップされたカウンターを想定します。 この動作により、システムが再起動され、カウンターがXNUMXから再開されると、データが誤ってスパイクされる可能性があります(つまり、カウンターメトリックタイプは、非常に速いレートでカウンターラップが発生したと見なされるため、大きな値が格納されます)。 このため、カウンターメトリックタイプが割り当てられているデータポイントの最大値を設定することをお勧めします。 これは、 有効な値の範囲 で説明されているように、データソース定義からデータポイントを構成するときに使用できるフィールド データポイントの概要.
カウンターメトリックタイプのユースケースがあることはまれです。 頻繁にラップするデータポイント(ギガビットインターフェイスのデータポイントや32ビットカウンターの使用など)を使用している場合を除き、カウンターの代わりに派生メトリックタイプを使用する必要があります。
メトリックタイプを導出する
派生メトリックタイプは、カウンターラップを修正しないことを除いて、カウンターに似ています。 派生物は負の値を返すことができます。
通常のデータポイント用に収集される生の出力の構成
データソース定義からデータポイントを構成する場合( データポイントの概要)、収集する生の出力を指定するフィールド(またはオプションのセット)があります。 ただし、これらのフィールド/オプションの表現は、データソースによって使用されている収集方法に応じて動的に変化します( コレクタ フィールド、を参照してください データソースの作成).
たとえば、このフィールドのタイトルは WMICLASS属性 WMIを介して収集され、タイトルが付けられたデータポイントを定義する場合 OID SNMPを介して収集されたデータポイントを定義する場合。 同様に、JMXを介して収集されたデータポイントを定義する場合、フィールド MBeanオブジェクト & MBean属性 表示。 また、もうXNUMXつの例として、スクリプトまたはバッチスクリプトを介して収集されたデータポイントを定義する場合、スクリプトソースデータオプションのリストが表示されます。 この動的なraw出力フィールドの構成の詳細については、次のWebサイトで入手可能な個々のサポート記事を参照してください。 データ収集方法 のトピックを参照してください。
通常のデータポイントの後処理の解釈方法
デバイスから収集されたデータを直接使用できる場合もありますが(たとえば、スクリプト収集メソッドを使用するときにスクリプトによって返される終了コード)、さらに解釈が必要な場合もあります。 収集方法についてさらに解釈できる場合は、 出力を次のように解釈します フィールドは、データポイントの構成(データソース定義にあります)で使用できるようになります。
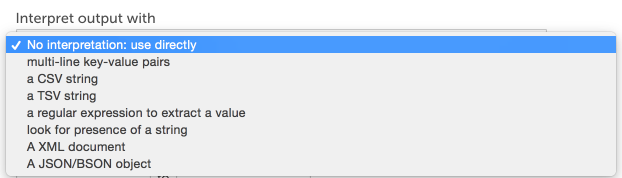
このフィールドは、収集された生の出力から目的の値を抽出する方法をLogicMonitorに通知します。 デフォルトの「解釈なし:直接使用」オプションが選択されている場合、生の出力がデータポイント値として使用されます。 通常、SNMP収集メソッドを使用するデータソースは、OIDの数値出力が保存および監視する必要のあるデータであるため、生の出力を未処理のままにします。
次のセクションでは、収集されたデータの処理に使用できるさまざまな解釈方法の概要を説明します。 特定のデータポイントで使用できるメソッドは、データソースで使用されている収集メソッドのタイプによって異なります( コレクタ フィールド、を参照してください データソースの作成).
複数行のキーと値のペア
この解釈方法では、複数行の文字列の生の測定値を、等号またはコロンで区切られたキーと値のペアのセットとして扱います。
Buffers=11023
BuffersAvailable=333
heapSize=245MB上記の複数行の文字列の場合、次に示すように、キーとして「Buffers」を指定することにより、バッファーの総数を抽出します。

注: キー名は、キーと値のペアごとに一意である必要があります。 生の測定出力に、異なる値とペアになっているXNUMXつの同一のキー名が含まれていて、区切り文字(等号またはコロン)が異なる場合、キーと値のペアのポストプロセッサーメソッドは値を抽出できません。
正規表現
正規表現を使用して、より複雑な文字列からデータを抽出できます。 正規表現の最初のキャプチャグループの内容(つまり、括弧内のテキスト)がデータポイントに割り当てられます。 たとえば、Apache DataSourceは正規表現を使用して、サーバーステータスページからカウンターを抽出します。 Webページ収集メソッドの生の出力は次のようになります。
Total Accesses: 8798099
Total kBytes: 328766882
CPULoad: 1.66756
Uptime: 80462合計アクセス数を抽出するには、次のようにデータポイントを定義できます。

テキストマッチ
文字列の存在を探す(TextMatch)は、生の出力内に文字列が存在するかどうかをテストします。 このメソッドは、テキストマッチングの正規表現をサポートします。 文字列が存在する場合は1を返し、存在しない場合は0を返します。
たとえば、Tomcatがホストで実行されているかどうかを確認するために、実行するスクリプトデータソースがある場合があります。
ps -ef | grep Java 定期的に。 パイプラインからの出力には、
org.apache.catalina.startup.Bootstrap スタート Tomcatが実行されている場合。
以下のデータポイントは、生の測定値が 出力 文字列が含まれています org.apache.catalina.startup.Bootstrap スタート。 はいの場合、データポイントは1になり、Tomcatが実行されていることを示します。そうでない場合、データポイントの値は0になります。

CSVとTSV
生の測定値がコンマ区切り値(CSV)またはタブ区切り値(TSV)の配列である場合は、CSVメソッドとTSVメソッドをそれぞれ使用して値を抽出できます。
ポストプロセッサがCSVおよびTSVメソッドで受け入れるパラメータには次のXNUMXつの形式があります。
- 単純な整数N。 入力の最初の行のN番目の要素を抽出します(要素はゼロから始まります)
- Index = Nx、Ny。 入力のNy番目の行のNx番目の要素を抽出します
- Line = regex index = Nx。 指定された正規表現に一致する最初の行のNx番目の要素を抽出します
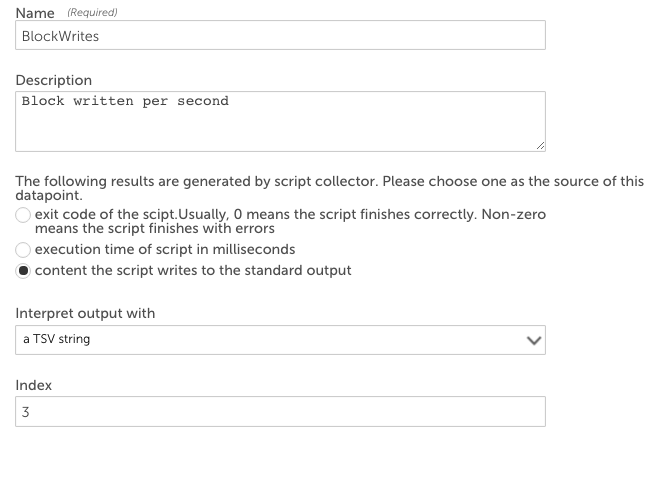
たとえば、スクリプトデータソースは実行されます iostat | grep'sda '| 頭-1 ハードディスク「sda」の統計を取得します。 出力はTSVアレイです。
sda 33.75 3.92 719.33 9145719 1679687042719.33番目の列(3)は、XNUMX秒あたりに書き込まれるブロックです。 TSV解釈方法を使用してこの値をデータポイントに抽出するには、出力を解釈する方法として「TSV文字列」を選択し、次に示すようにインデックスとして「XNUMX」を入力します。
HexExpr
「XNUMX進正規表現抽出値を持つXNUMX進文字列」(HexExpr)メソッドは、TCPおよびUDPデータ収集メソッドにのみ適用されます。 これは、これらの収集メソッドによって返されるTCPおよびUDPペイロードに適用されます。
ペイロードはバイト配列として扱われます。 次の形式で、1、2、4、または8(それぞれ、データ型byte、short、int、またはlongに対応)のオフセットと長さを指定します。
オフセット:長さ セクションに 正規表現 フィールド。 HexExprは、で始まるバイトの値(short、int、またはlong)を返します。
オフセット アレイの。
32ビット値を解釈するために、次のメソッドを選択して、基になるバイト順序を指定することもできます。
- 32進正規表現抽出値を持つビッグエンディアンのXNUMXビット整数XNUMX進文字列
- 32進正規表現抽出値を持つリトルエンディアンのXNUMXビット整数XNUMX進文字列
HexExprメソッドは、データポイントがDNSなどのバイナリパケットでフィールドの値を返すようにする場合に非常に役立ちます。
XML
XMLドキュメントの解釈では、XPath構文を使用して、XMLドキュメント内の要素と属性をナビゲートします。 たとえば、Webページの収集方法を使用して次のコンテンツを収集した場合…
<Order xmlns="https://www.example.com/myschema.xml">
<Customer>
<Name>Bill Buckram</Name>
<Cardnum>234 234 234 234</Cardnum>
</Customer>
<Manifest>
<Item>
<ID>209</ID>
<Title>Duke: A Biography of the Java Evangelist</Title>
<Quantity>1</Quantity>
<UnitPrice>12.75</UnitPrice>
</Item>
<Item>
<ID>204</ID>
<Title>
Making the Transition from C++ to the Java(tm) Language
</Title>
<Quantity>1</Quantity>
<UnitPrice>10.75</UnitPrice>
</Item>
</Manifest>
</Order>…上記のXMLページから「MakingtheTransition from C ++ to the Java Language」という本の注文IDを抽出するには、データポイント構成でHTTP応答本文をXMLドキュメントで解釈するように指定し、次のXpathを入力します。インクルード Xパス フィールド:
Order / Manifest / Item [normalize-space(Title)=” C ++からJava(tm)言語への移行”] / ID

任意 Xpath式 数値を返すものがサポートされています。 上記のサンプルXMLからデータを抽出するために使用できる他の例は次のとおりです。
- count(/ Order / Manifest / Item)
- sum(/ Order / Manifest / Item / UnitPrice)
JSONの
一部の収集メソッドは、生のデータポイントのXNUMXつの値としてJSONリテラル文字列を返します。 たとえば、HTTPリクエストを送信するWebページデータソースを作成できます
/ api / Overview RabbitMQサーバーに送信して、パフォーマンス情報を収集します。 RabbitMQは、次のようなJSONリテラル文字列を返します。
{
"management_version":"2.5.1",
"statistics_level":"fine",
"message_stats":[],
"queue_totals":{
"messages":0,
"messages_ready":0,
"messages_unacknowledged":0
},
"node":"rabbit@labpnginx01",
"statistics_db_node":"rabbit@labpnginx01",
"listeners":[
{
"node":"rabbit@labpnginx01",
"protocol":"amqp",
"host":"labpnginx01",
"ip_address":"::",
"port":5672
}
]
}JSON / BSONポストプロセッサを使用して、次のようにキュー内のメッセージの数を抽出するデータポイントを作成できます。
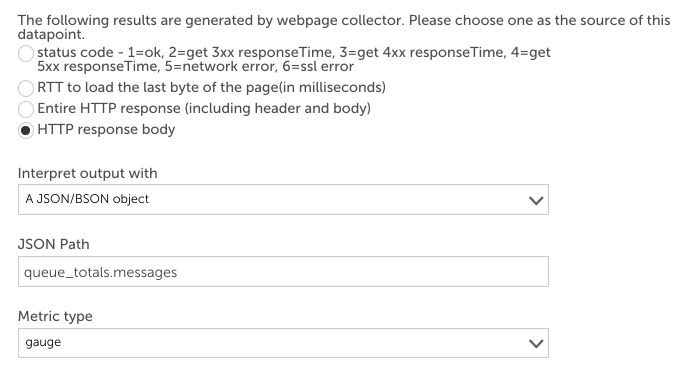
メンバーは、ドット演算子または添え字演算子を使用して取得できます。 LogicMonitorは、JavaScriptで使用される構文を使用してオブジェクトを識別します。 たとえば、「listeners [0] .port」は、上に表示された生データに対して5672を返します。
LogicMonitorは、オブジェクトまたは要素を選択するためのJSONパスをサポートしています。 XpathとJSONPathの構文要素の比較:
{
"store":{
"book":[
{
"title":"Harry Potter and the Sorcerer's Stone",
"price":"10.99"
},
{
"title":"Harry Potter and the Chamber of Secrets",
"price":"10.99"
},
{
"title":"Harry Potter and the Deathly Hallows",
"price":"9.99"
},
{
"title":"Lord of the Rings: The Return of the King",
"price":"17.99"
},
{
"title":"Lord of the Rings: The Two Towers",
"price":"17.99"
}
]
}
}すべての書籍の合計価格を取得するには、の集計関数を使用できます。
sum($。store.book [*]。price)、次に示す。

これを分解するには: 合計 集計関数です。 $ JsonPathの始まりです。 * 名前に関係なくすべてのオブジェクトを返すワイルドカードです。 次に、各オブジェクトの価格要素が返されます。
集計関数は、最外層でのみ使用できます。
正規表現フィルター=〜
正規表現フィルター=〜を使用して、指定した正規表現に一致するすべての要素を選択できます。 たとえば、ハリーポッターシリーズのすべての本の価格の合計を計算するには、次の式を使用できます。
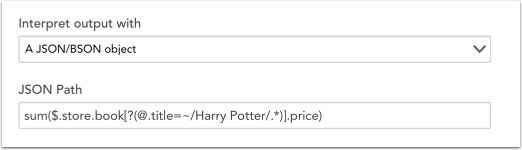
この式は、フィルター式を通過するストア内のすべての書籍(つまり、タイトルが正規表現「ハリーポッター」と一致する書籍)の価格の合計として分類できます。 正規表現一致は、フィルター式でのみ使用できます。
「@」は、例のブック配列内の各ブックオブジェクトを表す現在のオブジェクトを意味します。