
ログ異常検出
最終更新日: 11 年 2023 月 XNUMX 日監視対象リソースは、大量のログ データを生成します。 異常検出は、予想されるパターンに適合しないデータを識別します。 異常検出は、リソースの動作に関する洞察を得る方法であり、より深刻なイベントにエスカレートする前に問題を潜在的にキャッチできます。
LogicMonitor Logs 異常検出プロセス チャネルは、構造パターンを分析するパイプラインにイベントを記録し、着信ログ イベントが以前に確認されたかどうかを判断します。 これにより、IT 環境内の新規および変更されたログ イベントの精選された概要が得られます。
次に、LM ログの異常検出のしくみについて説明します。 一般的な LM プラットフォームでのログ異常検出については、次を参照してください。 異常検出の視覚化.
ログ異常とは何ですか?
異常とは、特定された通常のパターンから外れたログ データの変化です。 LM ログは、解析するログ イベント構造に基づいて異常を検出し、定期的なログ イベントの頻度または停止の変化を検出します。
LM Logs は、着信イベントの構造を分析して学習し、次のライブラリを構築します。 プロファイル イベントごとに。 イベントは XNUMX つのプロファイルにのみ関連付けることができます。 プロファイルは、複数の (ただし類似した) イベントに関連付けることができます。 新しい着信イベントは、学習したプロファイルと照合され、以前に見られたものか新しい異常かを判断します。
イベント プロファイル
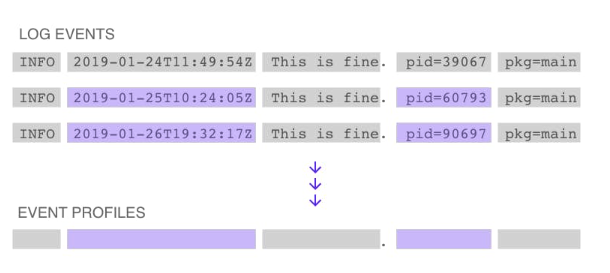
ログ イベントは、ログ データの個々の行です。 イベント プロファイルは、ログ イベントの発生元、カウント、到着時間、および頻度パターンに関する情報を含む、各ログ イベントの構造の記録です。
ログ イベントが受信されると、LM ログは と呼ばれるプロセスでその構造を識別します。 トークン化. これにより、メッセージの内容が一連の単語と句読点に分解され、各ログ イベントの構造に固有のハッシュが計算されます。 この構造ハッシュは、着信ログ イベントがそのリソースで以前に確認されたプロファイルと一致するかどうかを判断するために使用されます。
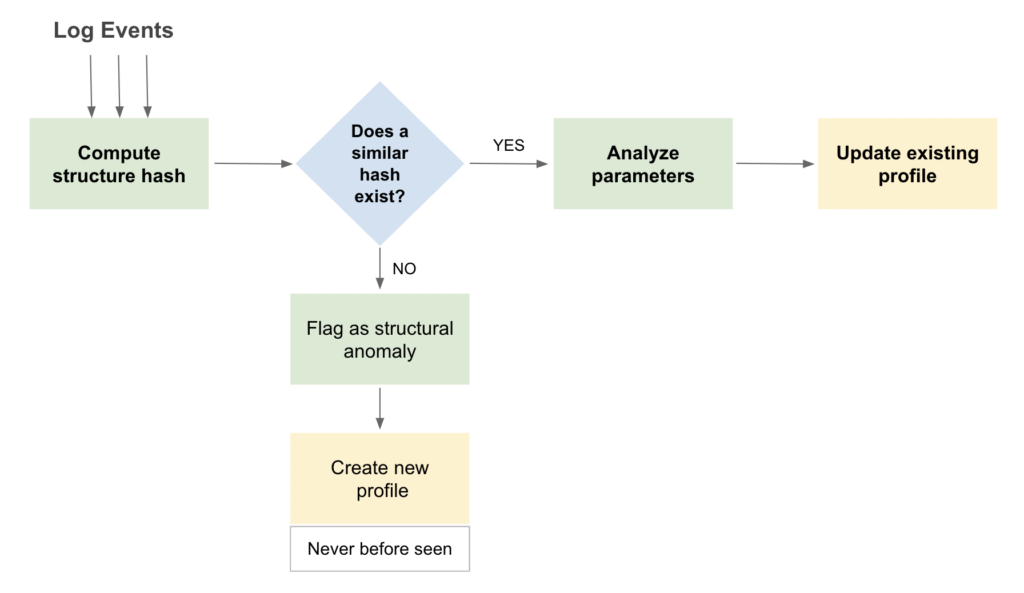
新しい各構造ハッシュは既存の構造と比較され、各リソースのプロファイル データベースに一致するものが存在するかどうかがチェックされます。 新しいハッシュが既存のハッシュと一致しない場合、LM Logs はデータベースに新しいプロファイルを作成し、このイベントをタイプの構造的異常としてフラグを立てます。 今まで見たことのない. LM ログは、より多くのデータを受信すると、イベント プロファイルを「学習」し、継続的に更新します。
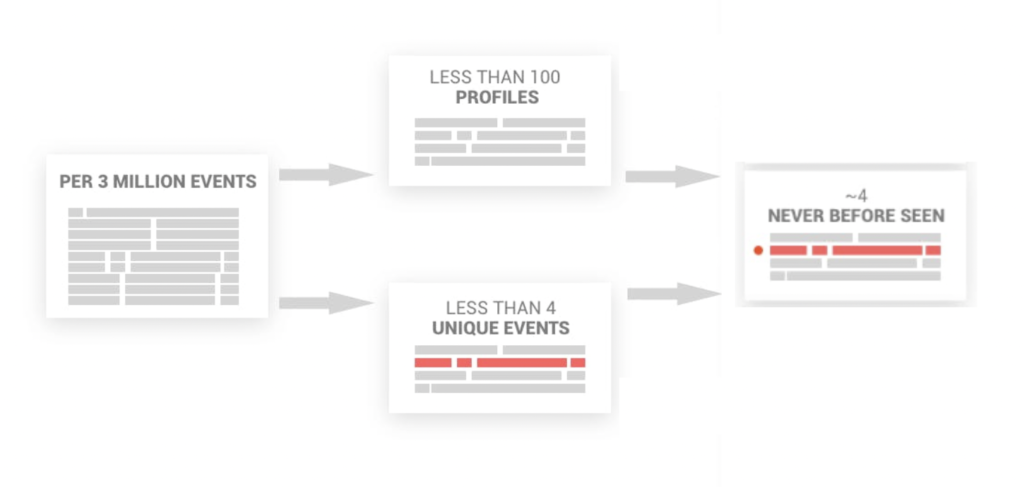
ログ イベントの大部分は、同じか類似した構造を持っています。 トークン化プロセスの別の部分では、構造の動的パラメーターを識別し、同様のプロファイルを動的パラメーターを持つ単一の集約プロファイルにマージします。 このマージの結果、分析するデータ量が少なくとも 99% 削減される可能性があります。
ログの異常の認識
プロファイル データベースを使用すると、着信ログ イベントが新しいか、以前に確認されたイベントと異なるかをすばやく判断できます。 既存の構造と一致しないログ イベントは、すぐに構造異常としてフラグが立てられます。

構造異常
構造異常は、LM ログが学習したログ イベント構造の確立されたパターンに適合しない、新しいログ イベントまたは大幅に変更されたログ イベントです。 これらは、システムまたは IT インフラストラクチャ全体で検出されていないプロファイルを持つイベントである可能性があります。 の 今まで見たことのない 監視対象のリソースで新しいイベントが発生したときにトリガーされる、構造的なタイプの異常です。
ログ異常の管理
特定の種類のログ イベントまたは異常を「常に表示」し、常に追跡して対処する必要がある場合があります。 これは、たとえば、すぐに解決するように通知する必要があるエラーまたは例外です。
このような場合は、 ログ パイプライン と追加 アラート条件、LM ログが学習した後にイベントを追跡します。 ログ パイプラインは、特定の一連のフィルターに一致するログ イベントに対して実行される一連の処理手順です。 追跡するログのフィルターを定義したら、アラート条件の設定など、他の処理手順を定義できます。
着信ログ イベントが定義済みのフィルターに一致すると、LM ログは、割り当てたアラート条件に基づいてイベントにフラグを立てます。 たとえば、重要なイベントが発生するたびにそれを強調表示したり、イベントを無視したりするアラート条件を定義できます。
注: LM Logs は異常を探すサービスであり、アラートを自動的に生成しません。 アラートは、ログ処理パイプラインを使用して定義したしきい値に基づいてのみ生成されます。
ログ異常の管理には、次に説明するタスクが含まれます。
ログ異常の表示
ログの異常は ログ インフラストラクチャ全体で未加工のログとログの異常を調べることができるページ。 の 異常 ボタンをクリックすると、クエリに異常が追加されます。 ログに異常がある場合、これらはグラフに紫色で表示されます。
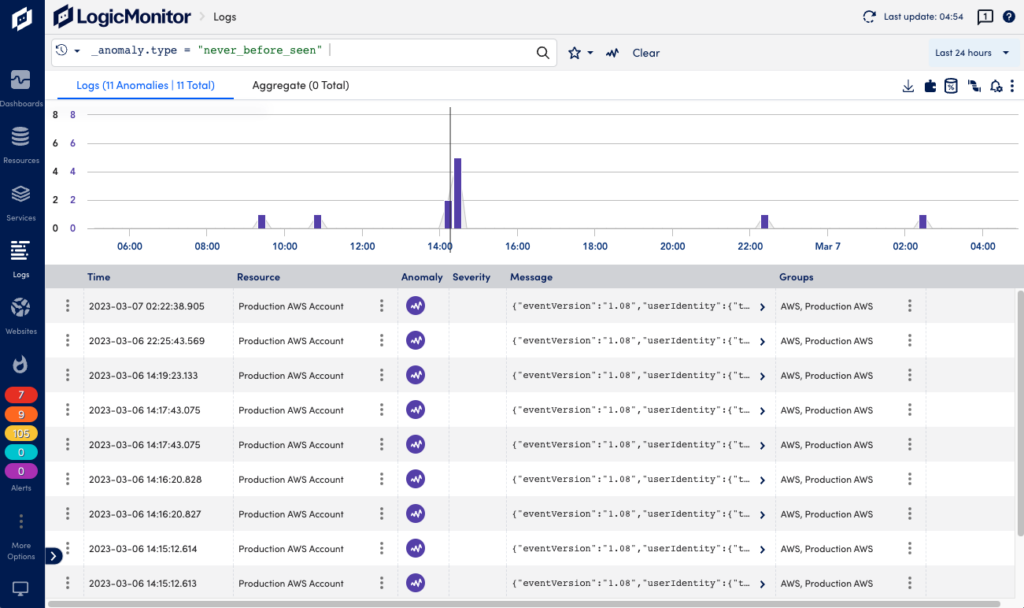
からログ異常にアクセスすることもできます。 グラフ タブの アラート このページには、メトリック アラートとともに状況に応じて表示され、トラブルシューティングを迅速化するのに役立ちます。 ログの異常によっては、[アラート] タブにアラートが自動的に作成されないことに注意してください。 アラートを作成するには、パイプラインとアラート条件を作成する必要があります。 詳細については、を参照してください。 ログとログの異常の確認.
注: 注: ログの異常検出は、サービス (resource.service.namespace) および名前空間 (resource.service.name) キーに基づいています。 取り込まれたログ イベントにこれらのキーが存在しない場合、異常検出は行われません。
特定のログ イベントと異常の追跡
LM ログがログ イベントを繰り返し確認すると、そのログ イベントは学習されたイベントの一部となり、強調表示されなくなります。 ログ イベントが追跡するほど重要である場合、問題を解決するためのアラート条件とコンテキスト情報を含むログ パイプラインを作成できます。 詳細については、「」を参照してください。 ログ処理パイプライン & ログアラート条件.
ログ アラートの監視
アラート このページには、LogicMonitor アカウント全体からのすべてのアラートが表示されます。 これには、ログからのアラートだけでなく、IT 環境の一部であるさまざまなデバイスやリソース、Web サイト、サービスからのアラートも含まれます。 詳細については、「」を参照してください。 アラートページからのアラートの管理.
ログ アラートのエスカレーション
エスカレーション チェーンを使用すると、LM ログがログ アラートのトリガーと条件にどのように応答するかを定義できます。 IT 環境内のリソースがオフラインになった場合、または運用環境で重大な異常が発生した場合には、LM ログでアクションを実行する必要があります。 たとえば、ユーザーに電子メールを送信したり、チームのチャット ルームに投稿したり、後で確認できるようにイベントにフラグを立てたりすることができます。 詳細については、を参照してください。 エスカレーションチェーン.