
JDBCデータ収集
最終更新日: 30 年 2020 月 XNUMX 日JDBCコレクターを使用すると、データベースにクエリを実行するデータソースを作成し、SQLクエリからデータを収集して保存し、それらにアラートを送信してグラフ化できます。
(データソースの[一般情報]セクションで)jdbcのコレクタータイプを選択すると、フォームにJDBC固有の属性セクションが表示されます。
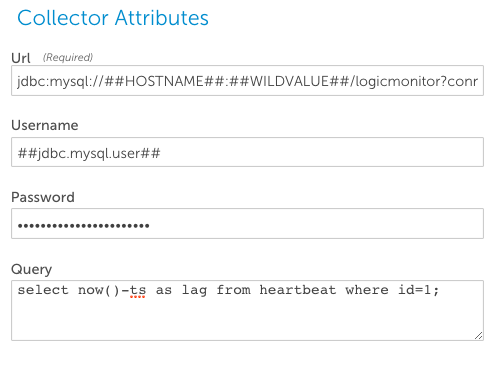
URL
URL データベースへの接続に使用されるjdbcURLです。 他の分野と同様に、 トークン 置換を使用してURLを汎用にすることができます(通常、## HOSTNAME ##トークンは、データソースが関連付けられているホストを置換するために使用されます。## WILDVALUE ##は、Active Discoveryデータソースで使用され、データベースが実行されていることが検出されたXNUMXつまたは複数のポート; ## DBNAME ##は、接続するデータベースを定義するために使用でき、ホストごと、またはグループごとに異なる場合があります。もちろん、任意のプロパティを任意の場所で使用できます。文字列に配置するか、文字列文字列を使用することもできます。)
URLの例:
jdbc:oracle:thin:@//##HOSTNAME##:1521/##DBNAME##jdbc:postgresql://##HOSTNAME##:##WILDVALUE##/##DBNAME##jdbc:sqlserver://##HOSTNAME##:##DBPORT##;databaseName=##DBNAME##;integratedSecurity=truejdbc:mysql://##HOSTNAME##:3306/##DBNAME##?connectTimeout=30000&socketTimeout=30000jdbc:sybase:Tds:##HOSTNAME##:##DBPORT##/##DBNAME##SyBase URLでは、ホスト名の前にスラッシュを付ける必要がないことに注意してください。
ユーザー名パスワード
& password データベースへの接続に使用される資格情報です。 これらは、このデータソースに固有のリテラルとして入力できますが、通常、LogicMonitorシステムの残りの部分で使用されるのと同じトークン(## jdbc.DBTYPE.user ##および## jdbc.DBTYPE.pass ##)で埋められます。 、DBTYPEはmysql、oracle、postgres、またはmssqlです。 これにより、必要に応じて、プロパティを適切なレベルに設定するだけで、ホストまたはグループごとに資格情報を個別に指定できます。
注意:
- Microsoft SQL Serverには、Windows認証とSQLServer認証の2つの異なる認証モードがあります。 Windows認証はActiveDirectoryユーザーアカウントを使用しますが、SQL認証はSQLServer管理システム内で定義されたアカウントを使用します。 Windows認証を使用する場合は、データソースでユーザー名またはパスワードを定義しないでください。 コレクターの 次のように実行 資格情報は、データベースへのアクセスに使用されます。 これをホストレベルで上書きすることはできません。 SQL Server認証を使用する場合、データソースで定義されているユーザー名とパスワードには、実行するクエリを実行する権限が必要です。 認証モードの詳細については、を参照してください。 認証モードを選択する MSDNサイトにあります。
- MySQLデータベースを使用している場合は、パスワードに円記号(\)文字が含まれていないことを確認してください。
クエリー
クエリー データベースに対して実行されるSQLステートメントです。 最も有効なSQLステートメントをサポートしますs。 ただし、コレクターはexecuteQueryメソッドを使用するため、結果セットを返さないSQLステートメントはJDBCデータ収集ではサポートされていません。 このようなステートメントには、「INSERT」、「DELETE」、または「UPDATE」、および「ALTER」、「CREATE」、「DROP」、「RENAME」、または「TRUNCATE」を使用するステートメントが含まれます。
セミコロンで終わるクエリ(上の画像に示されている)は、SQL Developer / CLIを介してOracleで実行される場合、一般的であり、場合によっては必要になることに注意してください。 ただし、一部のJDBCドライバーは、セミコロンで終わるクエリを拒否するため、エラーが発生します。 トラブルシューティングの目的で、JDBCドライバーの使用時にクエリがエラーを返す場合は、セミコロンを使用してドライバーの互換性を確認してください。
JDBCデータポイントの定義
すべてのデータソースと同様に、JDBCデータソース用に少なくともXNUMXつのデータポイントを定義する必要があります。 見る データポイントの概要 データポイントの構成の詳細については。
クエリ応答時間の測定
クエリの実行にかかった時間を測定するには、データポイントを追加し、ソースを「クエリ実行時間(ミリ秒)」に設定します。
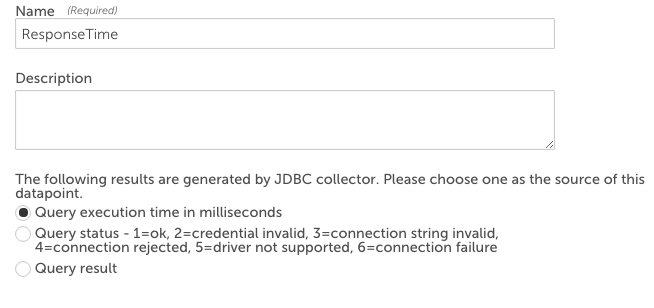
クエリ結果の解釈
クエリ結果を解釈するには、 使用価値 「出力」へのフィールド。 SQL結果の解釈に使用できるポストプロセッサメソッドはXNUMXつあります。
- 結果の最初の行の特定の列の値を使用します。 このポストプロセッサは最も簡単に使用できます。 ポストプロセッサパラメータとして列名を想定し、その列の最初の行の値を返します。
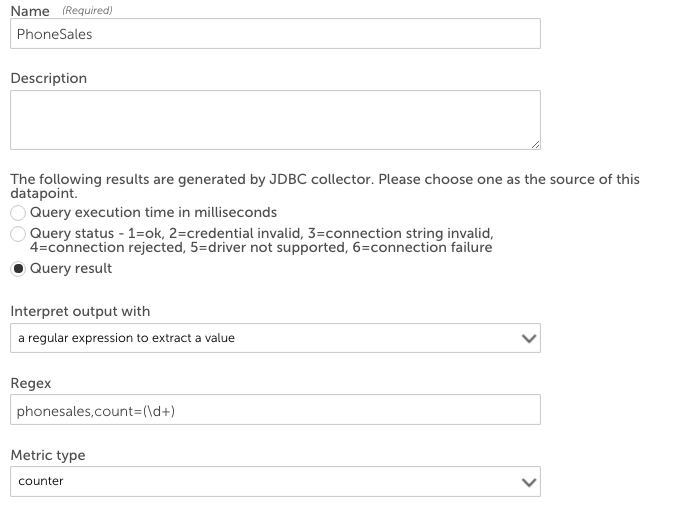
- 値を抽出するための正規表現: 返されたSQLに複数行の出力がある場合は、おそらく正規表現ポストプロセッサが必要になります。 ポストプロセッサパラメータとして正規表現が必要であり、式は格納する数値データを示す後方参照を返します。
例:次の形式のクエリ:
applicationeventsからアプリケーションを選択し、eventdate> NOW()– INTERVAL1時間のGROUPBYアプリケーションが次のような結果を返す可能性があるカウントとしてcount(*)。
ロジックモニターコレクターがこれらの結果を処理しているとき、正規表現の作成を容易にするために、各値の前に列名が追加されます。 したがって、上記の結果は次のように処理されます。
phonesalesについて報告された値は、「phonesales、count =(\ d +)」のポストプロセッサパラメータで正規表現を定義することで収集できます。
マシン情報の記入> という構文でなければなりません。例えば、
3. 文字列の存在を探します:テキスト一致ポストプロセッサは、SQL結果のポストプロセッサパラメータで指定されたテキストの存在を検索し、テキストが存在する場合は1を返し、存在しない場合は0を返します。
