
BatchScriptデータ収集
最終更新日: 14 年 2021 月 XNUMX 日概要
BatchScriptデータ収集メソッドは、次のようなデータソースに最適です。
- スクリプトを介して多数のインスタンスからデータを収集するか、または
- 単一のインスタンスからのデータのリクエストをサポートしていないデバイスからデータを収集します。
スクリプトデータ収集方法 スクリプトを介してデータを収集するためにも使用できますが、データは検出されたインスタンスごとにポーリングされます。 多数のインスタンスにわたって収集するデータソースの場合、これは非効率的であり、データの収集元のデバイスに過度の負荷がかかる可能性があります。 単一インスタンスからのデータの要求をサポートしないデバイスの場合、インスタンスごとにデータを返すために不要な複雑さを導入する必要があります。 BatchScriptデータ収集メソッドは、(インスタンスごとではなく)一度に複数のインスタンスのデータを収集することにより、これらの問題を解決します。
注:
- データポイントの解釈方法は、この収集方法の複数行のキーと値のペアとJSONに制限されています。 データポイントの解釈方法の詳細については、を参照してください。 通常のデータポイント.
- インスタンスのWILDVALUEに次の文字を含めることはできません。
:
#
\
spaceこれらの文字は、ActiveDiscoveryとコレクションの両方でWILDVALUEのアンダースコアまたはダッシュに置き換える必要があります。
BatchScriptコレクターのしくみ
スクリプトコレクターを使用するデータソースのデータを収集する場合と同様に、batchscriptコレクターは、指定されたスクリプト(埋め込みまたはアップロード)を実行し、プログラムの標準出力からその出力をキャプチャします。 プログラムが正しく終了した場合(終了ステータスコードが0であるかどうかを確認することで判別)、後処理メソッドが出力に適用されます。 このデータソースのデータポイントの値を抽出します(他のコレクターと同じ)。
出力フォーマット
スクリプトの出力は、JSONまたは行ベースのいずれかである必要があります。
行ベースの出力は、次の形式である必要があります。
JSON出力は次の形式である必要があります。
{
data: {
instance1: {
values: {
"key1": value11,
"key2": value12
}
},
instance2: {
values: {
"key1": value21,
"key2": value22
}
}
}
}BatchScriptデータ収集メソッドは、一度に複数のインスタンスのデータポイント情報を収集するため、インスタンス名を渡すには、各データポイント定義で## WILDVALUE ##トークンを使用する必要があります。 WILDVALUEにこのサポート記事で前述した無効な文字が含まれている場合、「NoData」が返されます。
上記の行ベースの出力を使用すると、データポイント定義は、次のキーを使用して、複数行とキーと値のペアの後処理メソッドを使用する必要があります。
- ## WILDVALUE ##。key1
- ## WILDVALUE ##。key2
上記のJSON出力を使用すると、データポイント定義は次のJSONパスを使用してJSON / BSONオブジェクトの後処理メソッドを使用する必要があります。
- data。## WILDVALUE ##。values.key1
- data。## WILDVALUE ##。values.key2
BatchScriptデータ収集の例
スクリプトが次の出力を生成する場合:
次に、IOPSデータポイント定義は次のようなキーと値のペアの後処理方法を使用できます。
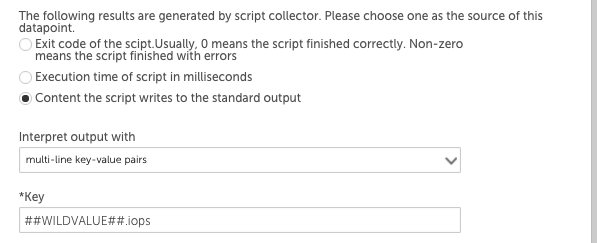
## WILDVALUE ##トークンはdisk1、次にdisk2に置き換えられるため、このデータポイントは各インスタンスのIOPS値を返します。 スループットデータポイント定義では、[キー]フィールドに「## WILDVALUE ##。throughput」が含まれます。