
コレクターのパフォーマンス
最終更新日: 26 年 2024 月 XNUMX 日LogicMonitorのコレクターは、ほとんどの環境で適切に機能するように構成されていますが、調整が必要な場合があります。
パフォーマンスの概要
コレクターのリソース消費(CPUとメモリー)とパフォーマンスの間にはトレードオフがあります。 デフォルトでは、コレクターは多くのリソースを消費しないため、コレクターがさまざまな作業を行っていない大規模な環境(たとえば、SNMPの混合ではなく、ほぼすべてのJMXコレクションを行うコレクター)では、コレクターの調整が必要になる場合があります。 JMXおよびJDBC)、または多くのデバイスが応答しない環境。 チューニングには、コレクターの構成の調整が含まれる場合もあれば、ワークロードの再分散が含まれる場合もあります。
コレクターが監視していたのと同じデバイスを処理できなくなる一般的な理由は、一部のデバイスが応答しなくなった場合です。 たとえば、コレクターがキューイングなしで100台のデバイスを監視しているが、タスクキューイングの表示を開始した場合、またはタスクをスケジュールできない場合、これは一部のデバイスからデータを収集できなくなったことが原因である可能性があります。 JMXを介してこれらすべてのデバイスと通信していて、各デバイスが通常200ミリ秒でJMXクエリに応答した場合、すべてのデバイスを簡単に循環できます。 ただし、JMX資格情報が10個のホストで不一致になり、LogicMonitorクエリに応答しない場合、コレクターは構成されたJMXタイムアウトまでスレッドを開いたままにします。 これで、いくつかのスレッドを開いたままにして、決して来ない応答を待ちます。 チューニングはこの状況で役立ちます。
コレクターにチューニングが必要かどうかはどうすればわかりますか?
設定したと仮定します コレクターの監視、コレクターがタスクをスケジュールできない場合は、コレクターデータ収集タスクデータソースからアラートが送信されます。 これは、データソースのスケジュールに従ってデータが収集されていないため、コレクターのワークロードを調整する必要があることを明確に示しています。 これにより、グラフにギャップが生じる可能性があります。 注目すべきもうXNUMXつの指標は、タスクキュー内の要素の存在です。 これは、コレクターがタスクのスケジュールを待機する必要があるが、タスクが適切な時間内に完了していることを示しています。したがって、コレクターが構成済みの容量に近づいていることを示す主要な指標です。
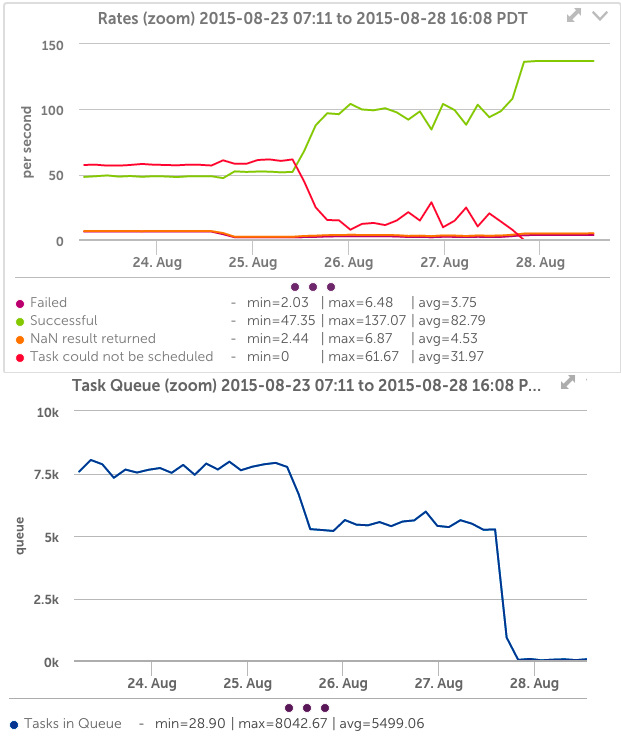
以下のグラフを見ると、コレクターのデータソースが過負荷のコレクターを明確に示していることがわかります。スケジュールできないタスクが多数あり、タスクキューが非常に高くなっています。 調整後(26月XNUMX日)、成功するタスクの数は増加します。 スケジュールされていないタスクは、タスクキューと同様にゼロになります。
優れたプロアクティブな動作は、コレクターダッシュボードを作成し、すべてのデバイス上のデータ収集タスクデータソースのすべてのインスタンスのデータポイントUnavailableScheduleTaskRateによる上位10のコレクターを示すカスタムグラフと、TasksCountInQueueによる上位10のコレクターを示すカスタムグラフを作成することです。 各コレクターにこれらのデータソースのインスタンスが多数ある場合(収集メソッドごとにXNUMXつ)、カスタムグラフのインスタンス制限を超えないように、特定の収集メソッドをインスタンス(snmp、jmxなど)として指定する必要がある場合があります。 それ以外の場合は、インスタンスをスター(*)に設定して、すべてのメソッドをXNUMXつのグラフに表示します。
コレクターのチューニング
コレクターを調整する最も簡単な方法は、単に コレクターサイズ。 小さなコレクターは2GBのメモリしか使用しませんが、より大きなサイズにアップグレードすると、より多くの作業を実行できます(コレクターを実行しているサーバーには、使用可能なメモリがあります)。 コレクターの構成は、で説明されているように、手動で変更することもできます。 コレクター構成ファイルの編集.
一般に、コレクターの調整が必要になる可能性のあるXNUMXつのケースがあります。
- デバイスが応答しないとき
- コレクターがワークロードに追いつけない場合
多くの場合、コレクターサイズを増やすことで両方に対処できます。これは、最初のステップです。 ただし、すでにサイズを大きくしてみてもパフォーマンスの問題が発生する場合は、少し微調整すると役立つ場合があります。
デバイスが応答しない
デバイスの資格情報が変更された、デバイスがオフラインである、LogicMonitor資格情報が正しく設定されていないなどの理由で、デバイスがコレクターからのクエリに応答できない場合は、デバイスでプロトコルが応答しないというアラートが表示されます。 この状況での最善のアプローチは、根本的な問題を修正する(資格情報を設定するなど)ことです。これにより、デバイスで監視を再開できます。 ただし、これが常に可能であるとは限りません。 から検証できます コレクターデバッグウィンドウ ([設定]…[コレクター]…[コレクターの管理]…[サポート]…[デバッグコマンドの実行]の下)この問題がコレクターに影響を与えているかどうか。 コマンドを実行した場合 !tlist c = METHOD、methodが問題のデータ収集メソッド(jmx、snmp、WMIなど)である場合、コレクターがスケジュールしたそのタイプのすべてのタスクのリストが表示されます。
タイムアウトまたは無応答が原因で失敗したタスクが多数ある場合、それらのタスクは、そのプロトコルのタイムアウト期間中、スレッドをビジー状態に保ちます。 この状況では、構成されたタイムアウトを減らして、スレッドが長時間ブロックされないようにすることが適切な場合があります。 JMXタイムアウトのデフォルトは、ある時点で30秒でした。これは、コンピューターが応答するのに非常に長い時間です。 これを5秒(現在のデフォルト)に設定すると、応答しないデバイスの場合、6倍の数のタスクを同時に処理できます。 タイムアウトを設定するときは、環境に適していることを確認するように注意する必要があります。 JMXタイムアウトを5秒に設定するのが適切な場合もありますが、Webページのレンダリングに時間がかかる場合があるため、Webページコレクターは30秒のままにすることができます。 デバイスが応答するよりも短い期間にタイムアウトを設定すると、監視に悪影響を及ぼします。
プロトコルのタイムアウトを変更するには、[コレクター構成]ウィンドウからコレクター構成を手動で編集する必要があります。 必要なプロトコルのタイムアウトを変更するには、collector。*。timeoutパラメーターを編集します(例:collector.jmx.timeout = 30をcollector.jmx.timeout = 5に変更します)。
スレッドの数を増やしたり、タイムアウト期間を短縮したりする必要がある場合もあります。以下のセクションを参照してください。
コレクターはワークロードに追いつくことができません
コレクターがまだタスクをスケジュールできないことを報告している場合は、収集メソッドのスレッド数を増やすことが適切な場合があります。 これにより、コレクターはより多くの作業を同時に実行できますが(特に、一部のスレッドがタイムアウトを待機している場合)、コレクターのCPU使用率も増加します。
収集メソッドで使用できるスレッドを増やすには、 コレクター構成ウィンドウからコレクター構成を手動で編集する必要があります。 collect。*。threadpoolパラメーターを編集して、必要なプロトコルのスレッドプール割り当てを変更します(例:collector.jmx.threadpool = 50をcollector.jmx.threadpool = 150に変更します)。
スレッドプールの設定を徐々に増やすことをお勧めします。現在の設定をXNUMX倍にしてから、動作を観察してください。 コレクターのCPU使用率とヒープ使用率の変化に注意してください。スレッドが増えると、CPUの使用量が増え、JVMヒープへの要求が増えます。 コレクターヒープの使用量(コレクターデータソースのコレクターJVMステータスの下に表示)が制限に近づいている場合は、それも増やす必要があります。
コレクターのスレッドが増加し、ヒープが増加した場合、 まだ ワークロードに追いつけない(またはCPU容量に達しています)–別のコレクターを追加し、コレクター間でワークロードを分割するときが来ました。