
JMXデータ収集
最終更新日: 30 年 2022 月 XNUMX 日JMXコレクターは、公開されたMBeanを使用してJavaアプリケーションからデータを収集するために使用されます。 JMXコレクションの構成に関する問題については、を参照してください。 このページ.
MBeanは、ドメインとプロパティのリストの組み合わせによって識別されます。 たとえば、domain = java.langおよびプロパティtype = Memoryは、JVMのメモリ使用量を報告するMBeanを識別します。
各MBeanは、名前で照会および収集できるXNUMXつ以上の属性を公開します。
MBean属性は次のようになります。
- int、long、double、StringなどのプリミティブJavaデータ型
- データの配列(「データ」自体は、プリミティブデータ型、データの配列、データのハッシュなどである可能性があります)
- データのハッシュ
LogicMonitor は、各属性がプリミティブ データ型になるように完全に指定されている限り、上記のすべてのデータ型を処理できます。 ただし、LogicMonitor は現在、ドット/ピリオドを含む JMX クエリをサポートしていないことに注意してください (つまり、 「。」 ) それらが配列の一部ではない場合、たとえばrep.Containerの属性名。
収集するJMXオブジェクトを指定するときは、以下を指定する必要があります。
- 名前–オブジェクトを識別するために使用されます
- MBean ObjectName –MBeanのJMXドメインとパスを指定するために使用されます
- Mbean属性–収集する属性を指定するために使用されます。
例:単純なケース:

収集される属性が複雑なオブジェクトの一部である場合は、ピリオド区切り記号を使用して修飾できます。

また、必要に応じて、複数レベルのセレクターを指定できます。 たとえば、LogicMonitor ドメインで rrdfs タイプの MBean のインデックス「move」を持つマップの属性「key1」の値を収集するには、次のようにします。

CompositeDataとマップのサポート
MBean属性式は、CompositeDataとMapをサポートします。 たとえば、MBeanjava.lang:type = GarbageCollector、name = Copy 属性があります LastGcInfo その値はCompositeDataです(下の図を参照)。1
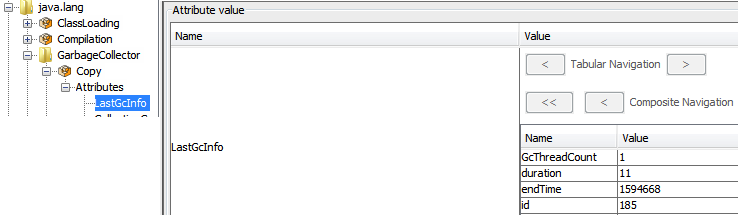
GcThreadCountの値にアクセスするには、属性式は「LastGcInfo.GcThreadCount「。 値がマップの場合、同じルールを使用できます。
TabularDataのサポート
MBean式はTabularDataをサポートします。 たとえば、MBean java.lang:type = GarbageCollector、name = Copy 属性LastGcInfoがあります。 その子値の1つであるmemoryUsageAfterGcはTabularDataです。 次の図は、そのスキーマとデータを示しています。XNUMX

テーブルには2つの列があります– 'キー'と'値'。 コラム 'キー'はテーブルにインデックスを付けるために使用されます(したがって、インデックス値を指定することで行を一意に見つけることができます。たとえば、 key =”コードキャッシュ” 1行目を返します)。 XNUMX番目の行の列 'value'の値を取得する場合、式は次のようになります。「lastGcInfo.memoryUsageAfterGc.EdenSpace.value」、 コラボレー 「エデンスペース」 は行を一意に見つけるための列「key」の値であり、「value」は値にアクセスする列の名前です。
TabularDataに複数のインデックス列がある場合があります。 次に例を示します(この例は偽造されていることに注意してください)。
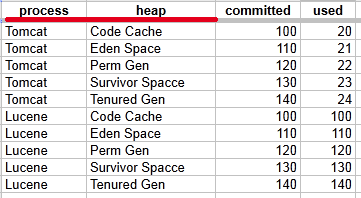
このTabularDataには4つの列があります。 「プロセス」列と「ヒープ」列はインデックス列です。 それらの値の組み合わせは、行を一意に見つけるために使用されます。 例えば、 process = Tomcat、heap =コードキャッシュ 最初の行を返します。
3行目の「コミット済み」列の値を取得するには、次の式を使用できます。LastGcInfo.memoryUsageAfterGc.Tomcat、Perm Gen.committed"、 どこ 'Tomcat、Perm Gen”はインデックス列の値(コンマで区切る)、 'コミットした'は、値にアクセスする列の名前です。
配列またはリストのサポート
Mbean式は、配列またはリストをサポートします。 たとえば、MBean java.lang:type = GarbageCollector、name = Copy 値が文字列配列(String []、下の図を参照)である属性MemoryPoolNamesがあります。
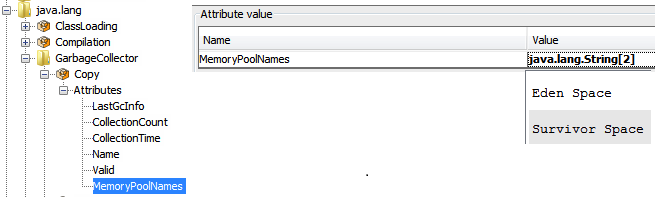
MemoryPoolNamesの最初の要素にアクセスするには、式は「メモリプール名.0「、ここで「0」は配列へのインデックスです(0ベース)。 リスト内の要素にアクセスするために同じルールが使用されます。
jmxコレクターは、デバイスのプロパティ(jmx.userおよびjmx.pass)からユーザー名とパスワードの情報を取得します。
コレクタへの JMX 属性の追加
Collector は、ドットを含む第 XNUMX レベルの JMX 属性をサポートしていません。 例えば、 jira-software.max.user.count. Collector は、このような属性を複合属性として扱い、ドットに基づいて分割します。 その結果、デバッグ ウィンドウで null ポインター例外が発生し、DataSource の Poll Now で NaN が発生する場合があります。
Collector に属性を分割しないように指示するには、ドット (.) の前に円記号 (\) を追加します。 例えば、 jira-software\.max\.user\.count. この追加により、Collector はエスケープ文字で区切られたドットだけを分割しなくなります。 文字列に他のドットが含まれている場合、それらは複合属性として扱われます。 これは、デバッグ ウィンドウから JMX 属性にアクセスする場合にも当てはまります。
追加の例:
| 属性フォーマット | コレクター コードで解釈される属性 |
jira-software\.max\.user\.count | jira-software.max.user.count |
jira-software\.max.user\.count | jira-software.max, user.count |
jira-software.max.user.count | jira-software, max, user, count |
jira-software.max.user\.count | jira-software, max, user.count |