
コレクター容量
最終更新日: 26 年 2024 月 XNUMX 日コレクターが処理できるデータの量は、コレクターの構成とリソースによって異なります。 コレクターのデータ収集の負荷とパフォーマンスを監視して、中断を最小限に抑え、コレクターがダウンしたときに通知することができます。 見る コレクターの監視.
大規模な環境で、コレクターの使用不可タスクレートデータソースでアラートが発生している場合は、コレクターを調整して監視容量を増やす必要がある場合があります。
デバイス容量の制限
次の表は、さまざまなサイズのコレクターの容量を示しています。 これは、XNUMX 秒あたりの要求数 (RPS) で測定されます (XNUMX 秒あたりのイベント数 (EPS) で測定される Syslog を除く)。
注:
- すべてのデバイスに 50 個のインスタンスをアタッチしました。 したがって、インスタンスの数を取得するには、デバイスの数に 50 を掛けます。たとえば、50 x 211 (デバイス) = 10550 インスタンスです。
- これらの測定値は推定値であり、実際の容量は運用環境によって異なる場合があります。
| プロトコール | 小さなコレクター | ミディアムコレクター | 大型コレクター | 特大(XL)コレクター | ダブルエクストララージ(XXL)コレクター |
| CPU: 1 インテル Xeon ファミリー システムメモリ:2GiB JVMの最大メモリ:1GiB | CPU: 2 インテル Xeon E5-2680v2 2.8GHz システムメモリ:4GiB JVMの最大メモリ:2GiB | CPU: 4 インテル Xeon E5-2680v2 2.8GHz システムメモリ:8GiB JVMの最大メモリ:4GiB | CPU:8 システムメモリ:16GiB JVMの最大メモリ:8GiB | CPU:16 システムメモリ:32GiB JVMの最大メモリ:16GiB | |
| SNMP v2c (Linux) | 300 台の標準デバイス 76RPS | 1000 台の標準デバイス 256RPS | 4000 台の標準デバイス 1024RPS | 8000 台の標準デバイス 2048RPS | 15000 台の標準デバイス 3840RPS |
| SNMP v3 | 855 台の標準デバイス 220RPS | 1087 台の標準デバイス 278RPS | 1520 台の標準デバイス 390RPS | 2660 台の標準デバイス 682RPS | 4180 台の標準デバイス 1074RPS |
| HTTP | 320 台の標準デバイス 160RPS | 1400 台の標準デバイス 735RPS | 2400 台の標準デバイス 1260RPS | 4500 台の標準デバイス 2000RPS | 7500 台の標準デバイス 3740RPS |
| WMI | 211 台の標準デバイス 77RPS | 287 台の標準デバイス 102RPS | 760 台の標準デバイス 272RPS | 1140 台の標準デバイス 409RPS | 1330 台の標準デバイス 433RPS |
| バッチスクリプト | 94 台の標準デバイス 5RPS | 124 台の標準デバイス 7RPS | 180 台の標準デバイス 11RPS | 295 台の標準デバイス 17RPS | 540 台の標準デバイス 32RPS |
| 演奏者 | 200 台の標準デバイス 87RPS | 400 台の標準デバイス 173RPS | 800 台の標準デバイス 347RPS | TBA | TBA |
| JMX | 1000 台の標準デバイス 416RPS | 2500 台の標準デバイス 1041RPS | 5000 台の標準デバイス 2083RPS | TBA | TBA |
| Syslog | TBD | 500 EPS (イベントサイズを100〜200バイトと想定) | 2500 EPS (イベントサイズを100〜200バイトと想定) | 4000 EPS (イベントサイズを100〜200バイトと想定) | 7000 EPS (イベントサイズを100〜200バイトと想定) |
容量は、監視対象デバイスごとに検出する必要があるインスタンスの数にも依存します。 たとえば、各デバイスが 10,000 インスタンスのロード バランサーである場合、コレクターの容量は少なくなります。 各デバイスが数百のインターフェイスを持つスイッチである場合、検出によって制限されるため、コレクターの容量が少なくなる可能性があります。
注:
- 本番の重要なアプリケーションとインフラストラクチャを監視するには、要件に応じて中規模以上のサイズのコレクターを使用することをお勧めします。 テスト目的で小さいサイズのコレクタを使用できます。
- コレクタが Amazon EC2 インスタンスで実行されている場合は、クレジット ベースのインスタンス タイプ (T5 など) ではなく、固定パフォーマンス インスタンス タイプ (M5 や C2 など) を使用することをお勧めします。
- この表にはナノコレクターのサイズは含まれていません。 ナノ コレクターはテスト用に使用されるため、推奨されるデバイス数の容量は割り当てられていません。
- JDK 11 (コレクター バージョン 28.400 以降でサポート) を使用するコレクターは、同じハードウェア上の以前の JDK 10 コレクターよりもメモリと CPU の使用量が約 8% 増加します。
VM のコレクターのメモリ要件
Collectorのシステムメモリ割り当ての一部は、スタンドアロンスクリプトエンジン(SSE)専用であり、デフォルトで有効になっており、スクリプトデータソース(Groovyスクリプト)の実行に使用されます。
| コレクターサイズ | SSEメモリ要件 |
| S | 0.5GiB |
| M | 1GiB |
| L | 2GiB |
| 特大 | 4GiB |
| ダブルエクストララージ | 8GiB |
一般に、SSEは、JVMに割り当てられたメモリ量の半分を必要とします。 メモリ要件は共有されませんが、SSE要件はJVMメモリ要件に追加されます。 コレクターに使用可能なこのメモリーがない場合、SSEは開始されず、「コレクターステータス」ダイアログに「SSEコレクターグループが見つかりません」と表示されます。 コレクターはSSEがなくても機能しますが、GroovyスクリプトはSSEではなくエージェントから実行されます。
コレクターがVMで実行されている場合、OSが空きメモリがあることを示しているため、このセーフガードをオーバーライドできます。 VMのこのバーストメモリ容量は、前述のシステムメモリ要件を超えてメモリ使用量を増やす可能性があります。 これは任意のサイズのコレクターで発生する可能性がありますが、小さなコレクターで発生する可能性がはるかに高くなります。
SSEを無効にし、追加のメモリ使用を防ぐには、コレクターを編集します agent.conf:
- 構成設定が次の場合
groovy.script.runner=sseに変更groovy.script.runner=agent. - 以前の設定が存在しない場合は、次の設定を更新します。
collector.script.asynchronous=false.
詳細については、を参照してください。 コレクター構成ファイルの編集.
NetFlow容量
次の表は、さまざまなサイズと OS プラットフォームにわたる NetFlow コレクタの容量を示しています。 これは、XNUMX 秒あたりのフロー (FPS) で測定されます。
注:
- 最適なパフォーマンスを得るには、NetFlow コレクタを NetFlow データの収集と処理にのみ使用することをお勧めします。
- 以下に挙げるすべての数値は、管理された条件下で社内の PSR ラボで取得されます。 したがって、コレクタの実際の容量は、顧客側の NetFlow トラフィックの性質に基づいて変化する可能性があります。
- NetFlow データの処理には CPU が集中します。 CPU 不足が発生した場合は、より多くのフローをサポートするために、まずコレクタ ホスト上のリソース (CPU コア) を増やすことをお勧めします。 CPU 容量を増やしても効果がない場合は、より大きなサイズのコレクターに切り替えることができます。
| OSプラットフォーム | メトリック | S コレクタ | M コレクタ | L コレクタ | 特大(XL)コレクター | ダブルエクストララージ(XXL)コレクター |
| Windows 64ビット Linux64ビット | サポートされるフロー/秒 | 7800 | 13797 | 23166 | 37418 | 52817 |
コレクタサイズの調整
特に、LogicMonitor ポータルからコレクタ サイズを調整できます。 性能調整 設置後のコレクタ容量の増加。
- MFAデバイスに移動する 設定 > コレクター.
- 下 コレクター タブで、サイズを調整するコレクターを選択します。
- 現在地に最も近い その他 オプションを選択してから コレクター構成.
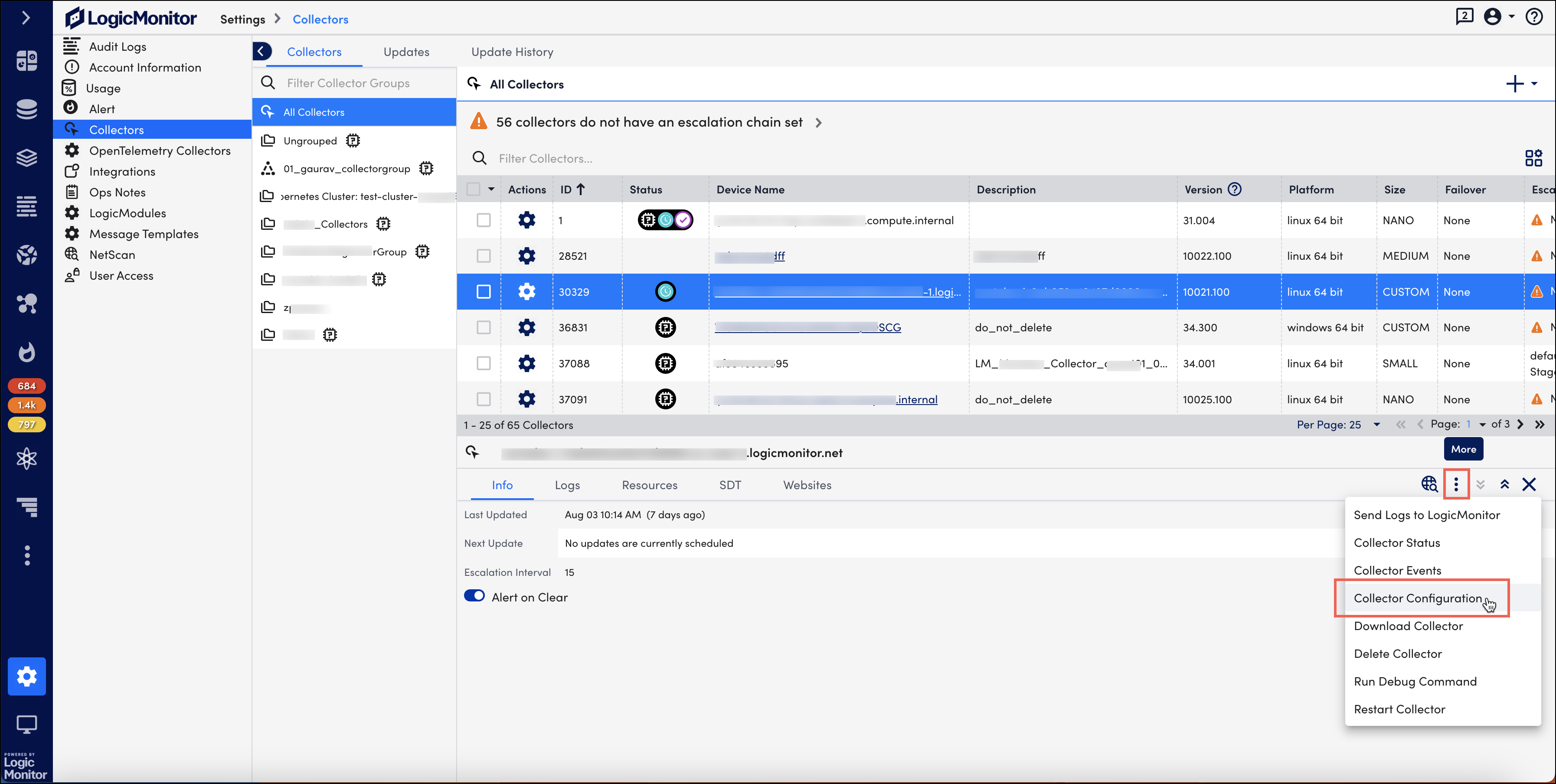
「コレクター構成」ページに、エージェント構成設定が表示されます。 - ドロップダウン メニューからコレクタ サイズを選択します。

- 選択 保存して再起動します。 LogicMonitor は、ホストに新しいコレクタ サイズをサポートするのに十分なメモリがあるかどうかを自動的に検証します。
注:
- 古いコレクターは、インストール後にパラメーターが変更されていない場合でも、ドロップダウンに現在のサイズを「カスタム(xGiB)」として表示します。 これは、コレクターがインストールされてからサイズの定義が変更されたためです。 コレクターの構成が最新であることを確認する場合は、必要なサイズ(または最初にインストールしたサイズ)を選択し、[保存して再起動]を選択します。
- コレクターのサイズを変更しても、そのサイズに関係のないパラメーターには影響しません。 以下のセクション「構成の詳細」にリストされているパラメーターは、コレクターのサイズの変更によって影響を受ける唯一のパラメーターです。
コレクターの構成パラメーターを手動で変更している場合、LogicMonitor は、ユーザーが選択した後に有効性チェックを実行します。 保存して再起動します 新しい構成でエラーが発生していないことを確認するため。 エラーが検出された場合は、欠落/重複した行が表示され、修正できるようになります。
小さなコレクター
| 設定ファイル | 計測パラメータ | 説明 |
| ラッパー.conf | wrapper.java.initmemory = 128 | コレクターの最小Javaヒープサイズ(MiB) |
| ラッパー.java.maxmemory = 1024 | コレクターの最大Javaヒープサイズ(MiB) | |
| sbproxy.conf | wmi.stage.threadpool.maxsize = 100 | sbwinproxy.exeでWMIクエリ/フェッチデータを処理するスレッドの最大サイズ |
| wmi.connection.threadpool.maxsize = 50 | sbwinproxy.exe内のリモートマシンに接続するWMIのスレッドの最大サイズ | |
| エージェント.conf | sbproxy.connector.capacity = 8192 | コレクターがsbwinproxyおよびsblinuxproxyに並行して送信できる要求の最大数 |
| Discover.workers = 10 | ActiveDiscoveryイテレーションにリソースを割り当てます | |
| autoprops.workers = 10 | APのスレッドプールサイズ | |
| reporter.persistent.queue.consume.rate = 10 | API呼び出しごとに報告されるデータエントリの最大数。 | |
| reporter.persistent.queue.consumer = 10 | バッファからの読み取りとレポートの実行に使用されるスレッド数。 | |
| コレクター.script.threadpool = 100 | スクリプトタスクを実行するための最大スレッド数。 | |
| ウェブサイト.conf | sse.max.spawn.process.count = 3 | 無し |
ミディアムコレクター
| 設定ファイル | 計測パラメータ | 説明 |
| ラッパー.conf | wrapper.java.initmemory = 512 | コレクターの最小Javaヒープサイズ(MiB) |
| ラッパー.java.maxmemory = 2048 | コレクターの最大Javaヒープサイズ(MiB) | |
| sbproxy.conf | wmi.stage.threadpool.maxsize = 200 | sbwinproxy.exeでWMIクエリ/フェッチデータを処理するスレッドの最大サイズ |
| wmi.connection.threadpool.maxsize = 100 | sbwinproxy.exe内のリモートマシンに接続するWMIのスレッドの最大サイズ | |
| エージェント.conf | sbproxy.connector.capacity = 8192 | コレクターがsbwinproxyおよびsblinuxproxyに並行して送信できる要求の最大数 |
| Discover.workers = 40 | ActiveDiscoveryイテレーションにリソースを割り当てます | |
| autoprops.workers = 10 | APのスレッドプールサイズ | |
| reporter.persistent.queue.consume.rate = 12 | API呼び出しごとに報告されるデータエントリの最大数。 | |
| reporter.persistent.queue.consumer = 10 | バッファからの読み取りとレポートの実行に使用されるスレッド数。 | |
| コレクター.script.threadpool = 200 | スクリプトタスクを実行するための最大スレッド数。 | |
| ウェブサイト.conf | sse.max.spawn.process.count = 5 | 無し |
大型コレクター
| 設定ファイル | 計測パラメータ | 説明 |
| ラッパー.conf | wrapper.java.initmemory = 1024 | コレクターの最小Javaヒープサイズ(MiB) |
| ラッパー.java.maxmemory = 4096 | コレクターの最大Javaヒープサイズ(MiB) | |
| sbproxy.conf | wmi.stage.threadpool.maxsize = 400 | sbwinproxy.exeでWMIクエリ/フェッチデータを処理するスレッドの最大サイズ |
| wmi.connection.threadpool.maxsize = 200 | sbwinproxy.exe内のリモートマシンに接続するWMIのスレッドの最大サイズ | |
| エージェント.conf | sbproxy.connector.capacity = 16384 | コレクターがsbwinproxyおよびsblinuxproxyに並行して送信できる要求の最大数 |
| Discover.workers = 80 | ActiveDiscoveryイテレーションにリソースを割り当てます | |
| autoprops.workers = 15 | APのスレッドプールサイズ | |
| reporter.persistent.queue.consume.rate = 12 | API呼び出しごとに報告されるデータエントリの最大数。 | |
| reporter.persistent.queue.consumer = 15 | バッファからの読み取りとレポートの実行に使用されるスレッド数。 | |
| コレクター.script.threadpool = 300 | スクリプトタスクを実行するための最大スレッド数。 | |
| ウェブサイト.conf | sse.max.spawn.process.count = 5 | 無し |
XLコレクター
| 設定ファイル | 計測パラメータ | 説明 |
| ラッパー.conf | wrapper.java.initmemory = 1024 | コレクターの最小Javaヒープサイズ(MiB) |
| ラッパー.java.maxmemory = 8192 | コレクターの最大Javaヒープサイズ(MiB) | |
| sbproxy.conf | wmi.stage.threadpool.maxsize = 800 | sbwinproxy.exeでWMIクエリ/フェッチデータを処理するスレッドの最大サイズ |
| wmi.connection.threadpool.maxsize = 400 | sbwinproxy.exe内のリモートマシンに接続するWMIのスレッドの最大サイズ | |
| エージェント.conf | sbproxy.connector.capacity = 32768 | コレクターがsbwinproxyおよびsblinuxproxyに並行して送信できる要求の最大数 |
| Discover.workers = 160 | ActiveDiscoveryイテレーションにリソースを割り当てます | |
| autoprops.workers = 20 | APのスレッドプールサイズ | |
| reporter.persistent.queue.consume.rate = 15 | API呼び出しごとに報告されるデータエントリの最大数。 | |
| reporter.persistent.queue.consumer = 20 | バッファからの読み取りとレポートの実行に使用されるスレッド数。 | |
| コレクター.script.threadpool = 400 | スクリプトタスクを実行するための最大スレッド数。 | |
| ウェブサイト.conf | sse.max.spawn.process.count = 10 | 無し |
XXLコレクター
| 設定ファイル | 計測パラメータ | 説明 |
| ラッパー.conf | wrapper.java.initmemory = 2048 | コレクターの最小Javaヒープサイズ(MiB) |
| ラッパー.java.maxmemory = 16384 | コレクターの最大Javaヒープサイズ(MiB) | |
| sbproxy.conf | wmi.stage.threadpool.maxsize = 1600 | sbwinproxy.exeでWMIクエリ/フェッチデータを処理するスレッドの最大サイズ |
| wmi.connection.threadpool.maxsize = 800 | sbwinproxy.exe内のリモートマシンに接続するWMIのスレッドの最大サイズ | |
| エージェント.conf | sbproxy.connector.capacity = 65536 | コレクターがsbwinproxyおよびsblinuxproxyに並行して送信できる要求の最大数 |
| Discover.workers = 320 | ActiveDiscoveryイテレーションにリソースを割り当てます | |
| autoprops.workers = 30 | APのスレッドプールサイズ | |
| reporter.persistent.queue.consume.rate = 20 | API呼び出しごとに報告されるデータエントリの最大数。 | |
| reporter.persistent.queue.consumer = 30 | バッファからの読み取りとレポートの実行に使用されるスレッド数。 | |
| コレクター.script.threadpool = 600 | スクリプトタスクを実行するための最大スレッド数。 | |
| ウェブサイト.conf | sse.max.spawn.process.count = 15 | 無し |
最小推奨ディスク容量
コレクターはメモリー内で動作しますが、キャッシュなどの操作には、ホスト上に使用可能なディスク容量が必要です。 必要なストレージの正確な量は、コレクターのサイズ、構成、NetFlowの使用状況、コレクターログの数などの要因によって異なります。
これらは、これらの要因に基づいて必要なディスク容量の例です。
- 真新しいインストールコレクターは約500MiBを使用します。
- コレクターログは最大で800MiBを使用します。
- 一時ファイル(つまり、アップグレードファイル)は1500MiB未満を使用します。
- レポートキャッシュデータは、デフォルトで500MiB未満を使用します(この図は、ラージコレクターの30分のキャッシュデータを表します)
- NetFlowを使用している場合、ディスク使用量は30GiB未満です。
合計すると、これは、コレクターディスクの使用量がNetFlowなしでは3.5GiB未満、NetFlowを有効にすると最大33.5GiBになることを意味します。