

LogicMonitor は現在、サービスと呼ばれる同じ機能を持つノードのグループを監視するためのソリューションを提供しています。 企業がよりオートスケーラブルで一時的なアーキテクチャに移行する中、LogicMonitor は、常に変化するこれらのサービスを継続的に監視できます。 また、これらのノードが効果的に使用されているかどうかを判断する方法も必要でした。 十分に活用されていないノードが複数ある場合、不要なコストになる可能性があります。 そのため、サービスのノードがどの程度使用されているかを判断するための統計的ソリューションを検討することにしました。 これにより、外れ値検出の使用と、サービスの全体的なバランスを決定する方法の調査が行われ、LogicMonitor が一緒に利用できる追加のメトリックを提供できるようになりました。 異常検出 時間の経過に伴うノード使用率の不一致を見つけるため。
この記事では、以下について説明します。
- 外れ値とは何ですか?
- 不均衡なサービスとは何ですか?
- 集計されたメトリックの外れ値検出よりも不均衡なサービス検出を使用するのはなぜですか?
- 不均衡なサービスに異常検出を使用する方法
- LogicMonitorはどのように不均衡なメトリックを使用しますか?
外れ値とは何ですか?
外れ値は、データセット内の他のポイントと大きく異なるデータ ポイントとして定義されます。 通常、外れ値は、収集されたデータのグループで何らかの異常またはエラーを判断します。 外れ値は通常、統計分析で問題を引き起こし、特に計算がデータの平均または標準偏差に依存する場合に、誤った結論につながります。 通常、外れ値の検出は、計算された上限と下限を超える値が外れ値と見なされる Tukey の Fences メソッドを使用して行われます。 ほとんどの人は、これらの例が XNUMX つの四分位数と上限と下限を示すボックス プロットを使用して視覚化されているのを見ます。
不均衡なサービスとは何ですか?
不均衡なサービスとは、一部のメトリックで均等に使用されていないインスタンスのグループを指します。 の使用量の増加に伴い マイクロサービス アーキテクチャでは、すべてのリソースが効率的かつ効果的に使用されていることを確認する必要があります。 そうでなければ、お金が無駄になり、そもそも水平方向に拡大する必要がありませんでした。 に ロードバランシング通常、ラウンドロビン戦略が採用されますが、ノードがより大きな、より複雑な要求を受信しているときに、ノードがより小さなタスクを取得している場合があります。 これは、これらの問題への洞察を得るために、不均衡なメトリックを確認する必要がある場所です。
集計されたメトリックの外れ値検出よりも不均衡なサービス検出を使用するのはなぜですか?
集約されたメトリック収集に依存しながら、異常値検出を使用して不規則なノードを見つけることは、ユーザーのニーズに応じて有望である可能性があります。 リクエスト数やHTTPS呼び出しなどの指標では、データポイントに大きな違いが見られる可能性があり、他のノードが使用されていない場合や一部が過剰に使用されている場合は、これらの違いが外れ値と見なされます。 その他の場合(CPU、メモリ、その他のパーセンタイル測定値)については、パーセンテージ(0-100)の境界が設定されているため、外れ値を計算することは非常に困難です。 これは、不均衡検出アルゴリズムがはるかに効果的である場所です。
外れ値検出が機能しない例
10個のサービスがあり、90個が90%のCPU使用率、10個がXNUMX%のサービスがある場合、ここでは外れ値がありますが、XNUMX個のノードがXNUMX%、XNUMX個がXNUMX%の場合を考えてみましょう。 この場合、ノードは確かに全体的に効率的に使用されていませんが、外れ値の検出に依存している場合、問題の兆候はありません。 外れ値検出を使用する場合のもうXNUMXつの問題は、より大きなデータセットが必要であり、いくつかの極値が含まれている必要がある一方で、不均衡を統計的に決定することで、任意の数のノードで使用でき、最小の差異が見つかることです。
不均衡なサービスに異常検出を使用する方法
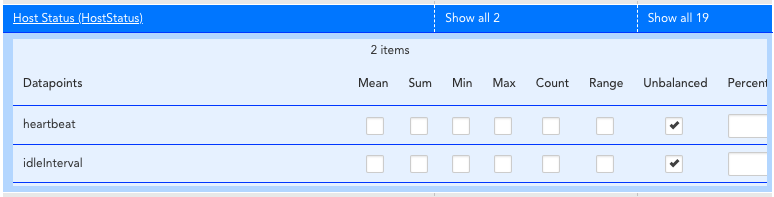
図1:不均衡な集計をサービスに追加する。

図2:新しい不均衡な集計関数のデータポイントの確認。
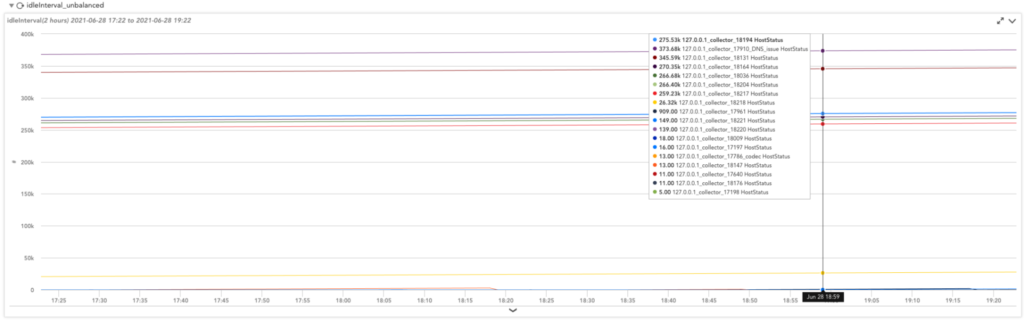
図3:サービス内の各インスタンスに関連するデータポイントを表示します。
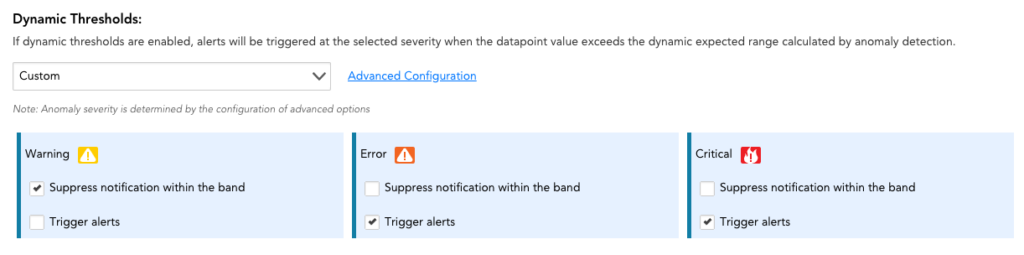
図4:ここでは、異常検出に基づいて決定される動的アラートを設定します。

図5:通知が必要になる前に、サービスがどのように不均衡になる可能性があるかをユーザーが知っている場合の静的アラートの設定。
LogicMonitorはどのように不均衡なメトリックを使用しますか?
LogicMonitorでは、独自の製品を使用してサービスを監視しています。 これにより、不均衡な指標を最大限に活用して、サービスがどの程度活用されているかを判断し、パフォーマンスを向上させるために必要なアクションを実行できます。
新しいバージョンの展開は、私たち自身のサービスにどのように影響しましたか?
現在監視しているサービスの例は、ポッド全体に複数のサービスがあるコレクターアダプターです。これは、大規模な顧客がいる場合に、ノードが均等に使用されていないことに気づきました。 これは、顧客に基づいてリクエストを分離する負荷管理システムが原因であると判断されたため、大規模な顧客の場合、すべてが同じポッドに存在していても、リクエスト率は小規模なものよりもはるかに大きくなります。
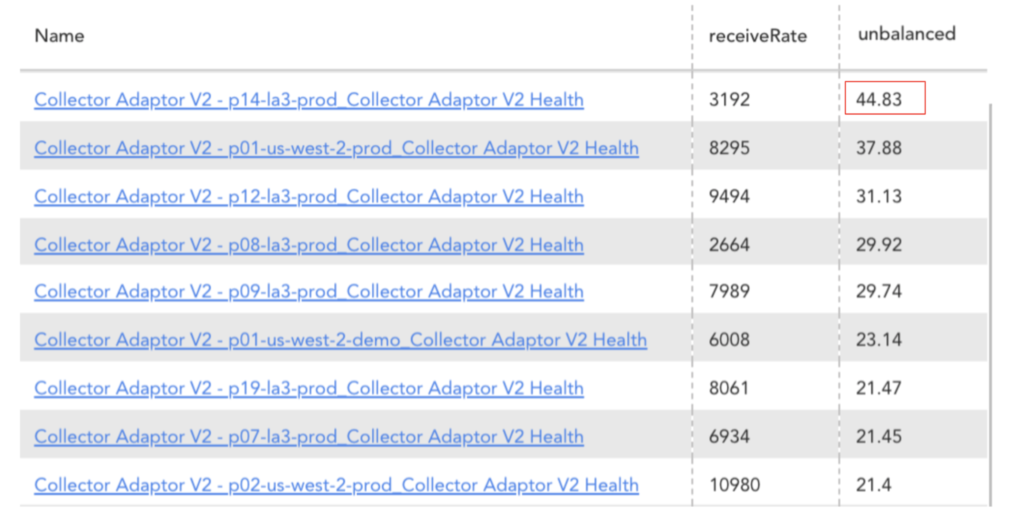
図6:コレクターアダプタサービスのレート要求の非効率性を見つけるために使用されている不均衡なメトリック。
このメトリックを利用できるようにすることで、これらの問題を早期に発見し、レビューが必要なサービスとノードを簡単に特定できるようになります。 CPUなどの他の使用率メトリックをより詳細に把握できるため、最初の問題を見つけるのではなく、ソリューションの調査に時間を費やすことができます。 最近、新しいバージョンのコレクターアダプターをデプロイした場合、CPU使用率に大きな変化が見られ、その後に図6に示す大きな不均衡インデックスが続きました。これにより、調査すべきことがあると判断しました。収集された他の集約されたメトリックと異常検出を使用して、より多くの情報を見つけることができました。
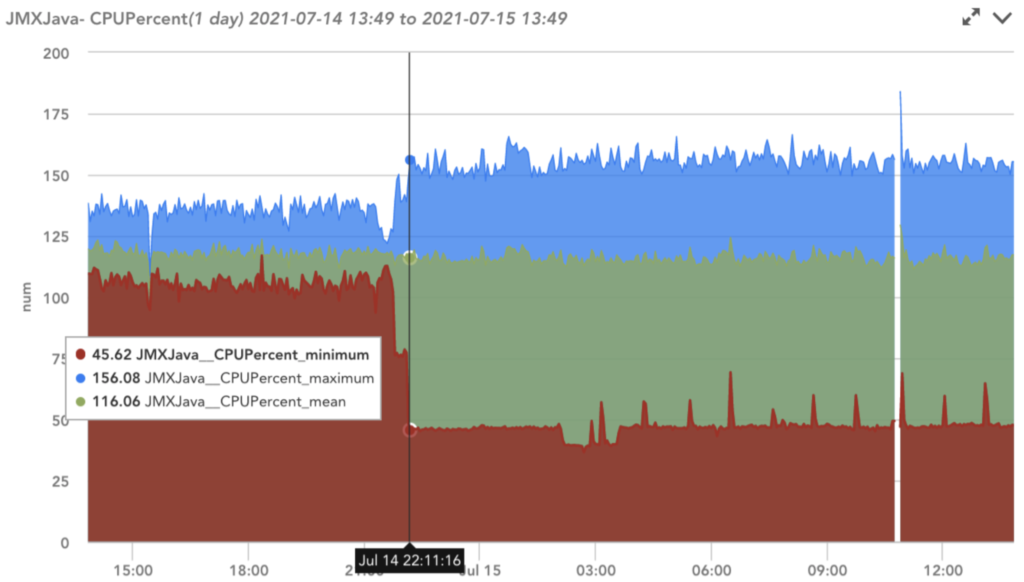
図7:アンバランスインデックスが45%のサービスで、展開により最大、最小、平均の間に大きな違いがあるCPU集約メトリックがあります。
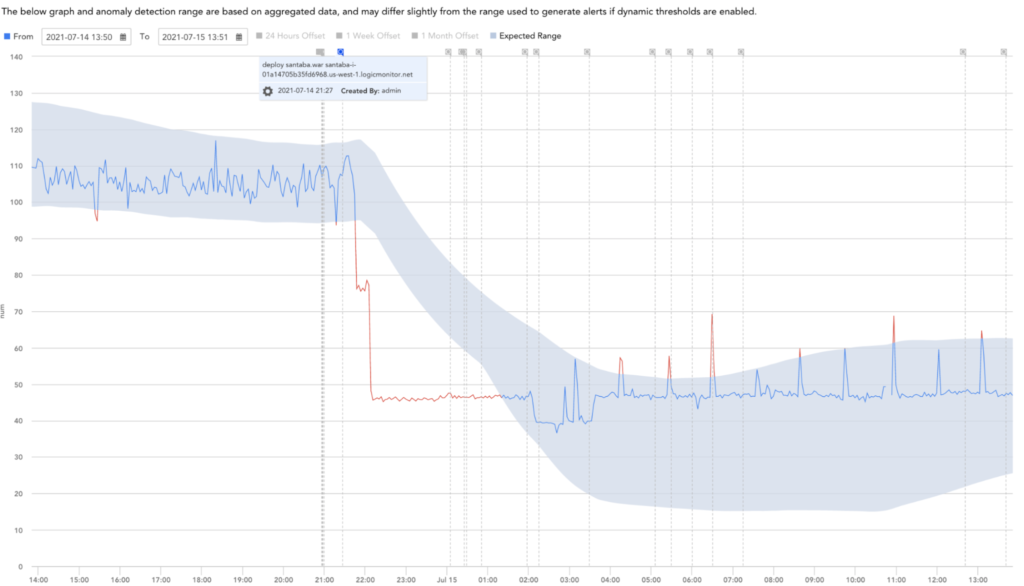
図8:CPU使用率の大幅な低下を示す異常検出分析と、最近の展開が原因であることを示すメモ。
まとめ
考えられる解決策として両方のオプションを検討した結果、外れ値の検出に依存するよりも、不均衡なサービス検出アルゴリズムを使用してユースケースをより適切に処理できると判断しました。 極値シナリオに依存することなく、大規模なサービスをすべてサポートしながら、小規模なサービスの使いやすさを向上させました。
16 年 2021 月 2022 日に最初に公開されました。XNUMX 年 XNUMX 月に更新されました。

