アマゾンウェブサービスElasticsearchServiceを使用すると、組織はElasticsearchクラスターをデプロイ、保護、実行できます。 AWS Elasticsearchは、大規模に運用するための費用対効果の高い方法です。
この記事では、以下について説明します。
Elasticsearchとは何ですか?
Elasticsearch アプリケーション、Webサイト、およびデータレイクカタログのクイック検索エクスペリエンスを提供する方法を提供します。 また、監視や ログを収集する インフラストラクチャとアプリケーションから。 Elasticsearchは、に基づくAWSのサービスです ElasticのオープンソースElasticsearch 「オープンソースの分散型RESTful検索エンジン」として造られました。 これは、データの高速で関連性のあるスケーラブルな検索を提供するように設計されています。
AWSCloudwatchメトリクス
Elasticsearchはデータポイントをに公開します アマゾンクラウドウォッチ Elasticsearchインスタンス用。 CloudWatchを使用すると、これらのデータポイントに関する統計を、メトリクスと呼ばれる時系列データの順序付けられたセットとして取得できます。 Elasticsearchサービスについて、Amazonはいくつかの基本的な指標とその 推奨されるCloudWatchアラーム.
なぜ独自のメトリックを追加する必要があるのですか?
LogicMonitorが導入されました 複雑なデータポイント 時間の経過に伴う、またはパーセンテージとしてのメトリック値に関する理解をもたらすことを試みます。 ClusterUsedSpaceなどの生の値を使用して使用可能な容量を追跡することは困難な作業です。 パーセンタイルを計算する複雑なデータポイントは、はるかに意味があり、警告が容易です。
クラスタ使用スペースパーセント =(ClusterUsedSpace /(ClusterUsedSpace + FreeStorageSpace))* 100
CloudWatchを使用すると、httpsエラーコード4xxおよび5xxをraw値として取得できます。 次の質問を検討してください。2xxメトリックの値5は良いですか、悪いですか。 そして、それはどれくらい良い(または悪い)ですか? 通常、私がこの質問をするとき、その人は「それはリクエストの数に依存します」と言うでしょう。 この場合も、パーセンタイルを計算する複雑なデータポイントの方がはるかに意味があり、警告が容易です。
リクエスト数5xxパーセント = 5xx /(5xx + 4xx + 3xx + 2xx)if(5xx + 4xx + 3xx + 2xx)> 0 else 0
リクエスト数4xxパーセント = 4xx /(5xx + 4xx + 3xx + 2xx)if(5xx + 4xx + 3xx + 2xx)> 0 else 0
主要な指標は何ですか?
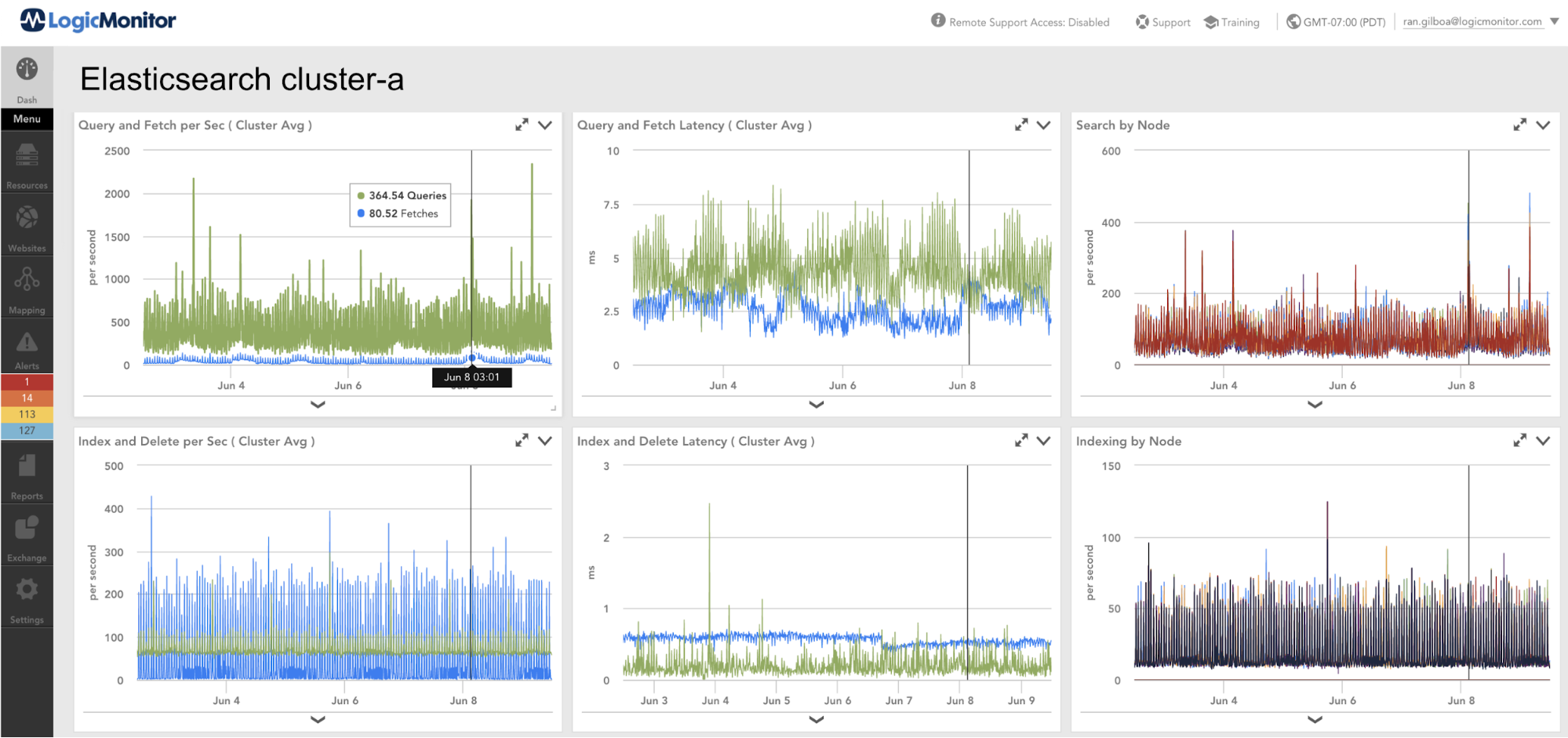
クラスター使用スペースパーセント (複雑なデータポイント)
使用されるクラスタースペースのパーセンテージを計算する複雑なデータポイント。 デフォルトでは、LogicMonitorは、85%が使用された場合の警告と、95%が使用された場合のエラーを推奨します。
クラスタ使用スペースパーセント =(ClusterUsedSpace /(ClusterUsedSpace + FreeStorageSpace))* 100
CPU使用率
クラスター内のデータノードに使用されるCPUリソースの平均最大パーセンテージ。 LogicMonitorは、85%の使用率で警告を、95%の使用率でエラーを推奨します。
クラスターステータス赤
これは、少なくとも0つのインデックスのプライマリシャードとレプリカシャードがクラスター内のノードに割り当てられていないことを示しています。 この値がXNUMXでない場合、LogicMonitorはエラーを推奨します。
クラスターステータス黄色
これは、少なくとも0つのインデックスのプライマリシャードとレプリカシャードがクラスター内のノードに割り当てられていないことを示しています。 この値がXNUMXでない場合、LogicMonitorはエラーを推奨します。Elasticsearchインスタンスのレプリケーションがない場合は、アラートを出さないようにこのメトリックを編集する必要があることに注意してください。
JVMメモリ圧力
このメトリックは、クラスター内のすべてのデータノードに使用されるJavaヒープの最大パーセンテージを示します。 この値が80を超える場合、LogicMonitorは警告を推奨します。
異常検出の動的しきい値を有効にするにはどうすればよいですか?
主要なメトリックに動的しきい値と静的しきい値を使用することが期待されていますが、他のユースケースもあります。
例
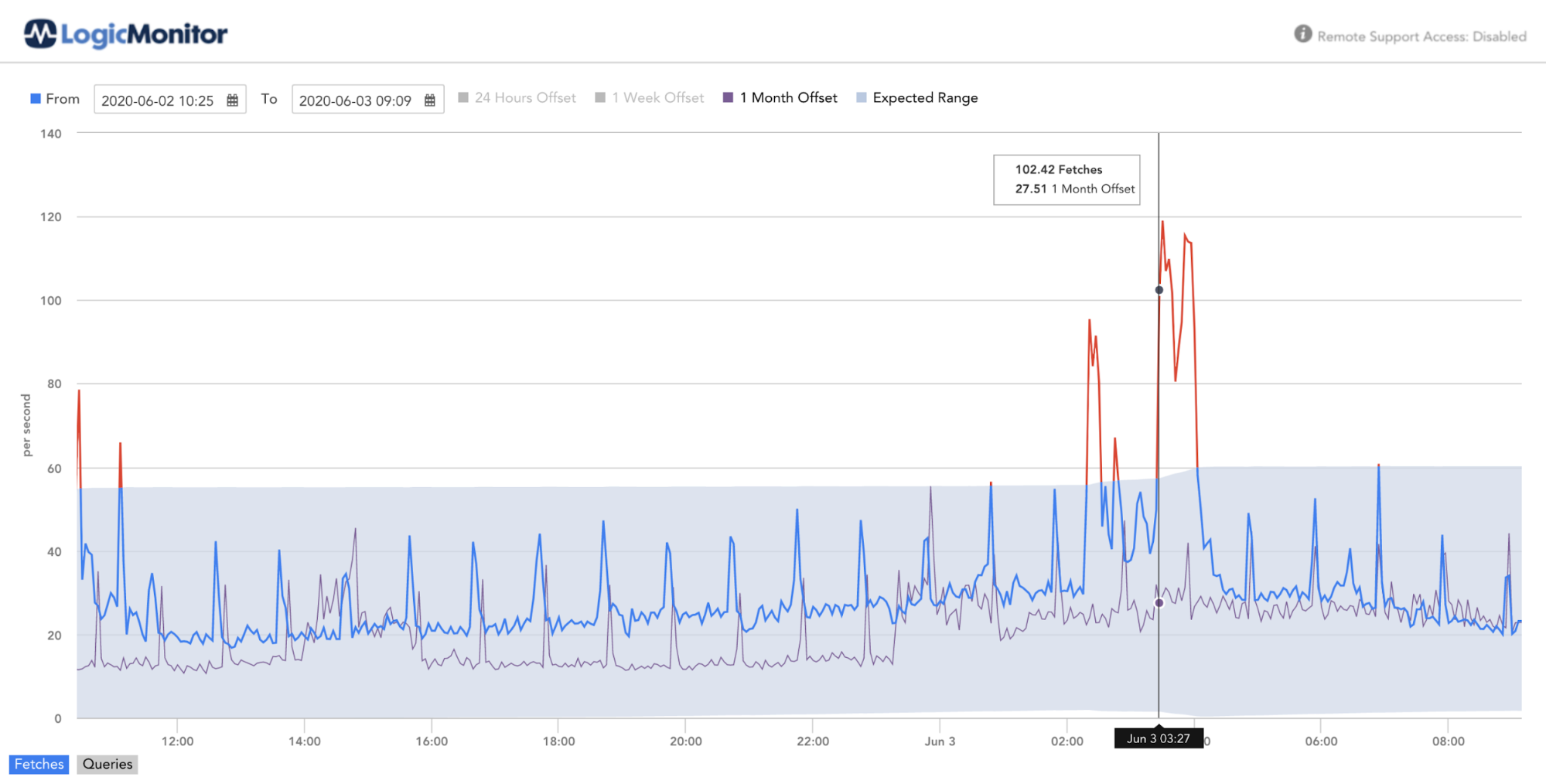
クエリとフェッチのレイテンシーの異常検出を有効にすることは、サービスの潜在的な劣化を示す方法であり、予想される操作に変化があった場合に事前に警告を発する方法です。
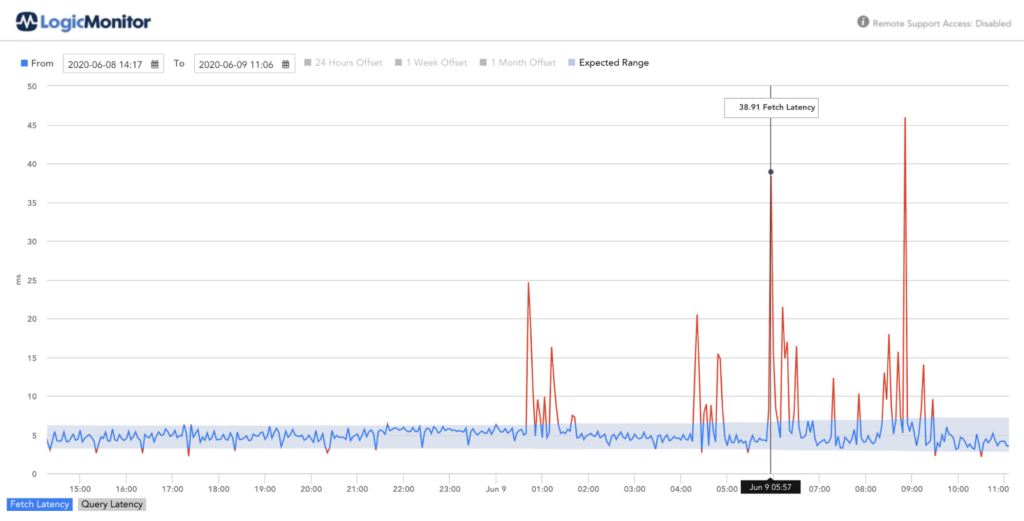
例
クエリおよびフェッチカウントの異常検出を有効にすることは、システムの潜在的な異常負荷(または新規顧客のオンボーディング)を示す方法です。