
AWSは驚異的な速度で新製品をリリースしているため、ユーザーがそれらのサービスのベストプラクティスやユースケースに追いつくのは困難です。 ITチームにとってのリスクは、ビジネスオペレーションを改善し、コストを節約し、ITパフォーマンスを最適化できるAWSサービスのリリースを見逃してしまうことです。
特に十分に活用されていないと思うサービスをもう一度見てみましょう。 AmazonのT2インスタンスタイプは新しいものではありませんが、よく知らない人には複雑に見える可能性があります。 の中に アマゾンの言葉、「T2インスタンスは、CPU全体を頻繁にまたは一貫して使用しないが、CPUパフォーマンスを向上させるためにバーストする必要があるワークロード用です。」 この定義は私には曖昧に思えます。 インスタンスがCPUを「頻繁に」使用する場合はどうなりますか? それは実際のパフォーマンスにどのように現れますか? 以下のように、大きく変化するCloudWatchとOSの統計を調整するにはどうすればよいですか?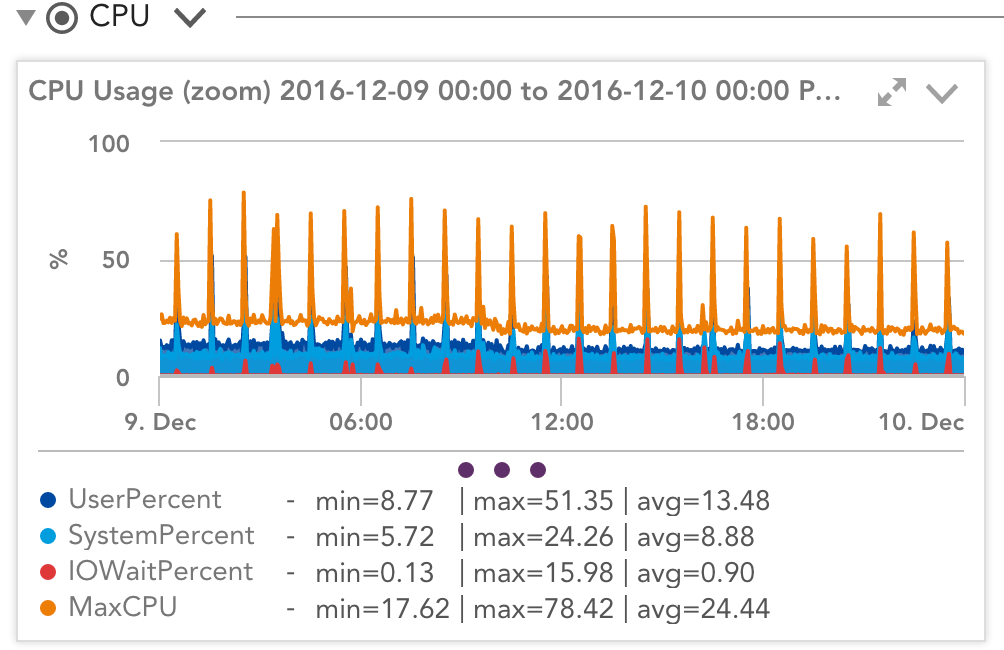
読む!
Amazon 説明して 「T2インスタンスのベースラインパフォーマンスとバースト能力は、CPUクレジットによって管理されます。 各T2インスタンスはCPUクレジットを継続的に受け取りますが、その割合はインスタンスのサイズによって異なります。 T2インスタンスは、アイドル状態のときにCPUクレジットを獲得し、アクティブなときにCPUクレジットを使用します。 CPUクレジットは、フルCPUコアのパフォーマンスをXNUMX分間提供します。」 そのため、インスタンスには常にCPUクレジットが「供給」され、CPUがアクティブになるとそれらが消費されます。 消費率がフィード率よりも低い場合、CPUCreditBalance(CloudWatchに表示されるメトリックス)が増加します。 それ以外の場合は減少します(または同じままになります)。
これを抽象化しないようにしましょう。T2.mediumを見て、 アマゾンは言う 40つのvCPUの24%のベースライン割り当てがあり、100時間あたり24の割合でクレジットを獲得します(各クレジットは40分間2%で実行される20つのvCPUを表します。したがって、2時間あたり20クレジットを獲得すると、インスタンスをで実行できます。 40つのvCPUの20%のベースライン)。 この割り当ては、T40.mediumインスタンスのXNUMXつのコアに分散されます。 注意すべき重要なことは、CPUクレジットは基本パフォーマンスレベルを維持するために使用されるということです。基本パフォーマンスレベルは、獲得したクレジットに加えて与えられるものではありません。 つまり、事実上、これは、デュアルコアTXNUMX.mediumでXNUMX%のCPU負荷を維持できることを意味します(XNUMX%のXNUMXつのコアがXNUMX%のベースライン割り当てに結合されるため)。 実際には、クレジットが完全になくなることがあるため、XNUMX%をわずかに超える額が得られますが、AmazonではXNUMX%のベースライン作業を行うことができます。 また、一時的にクレジット残高があり、短期間でベースラインを超える金額を取得できる場合もあります。
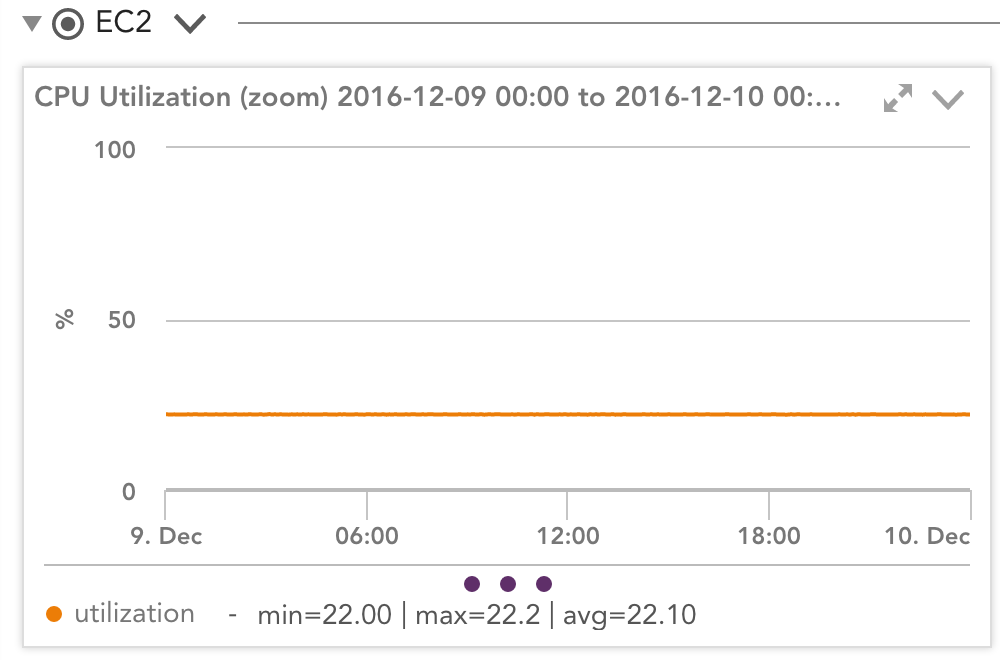
たとえば、高いワークロードを実行しているT2.mediumインスタンスを見ると、すべてのクレジットが使用されているため、LogicMonitorから確認できます。 CloudWatchモニタリング このインスタンスが常に21.7%で実行されているとAmazonが考えるグラフ: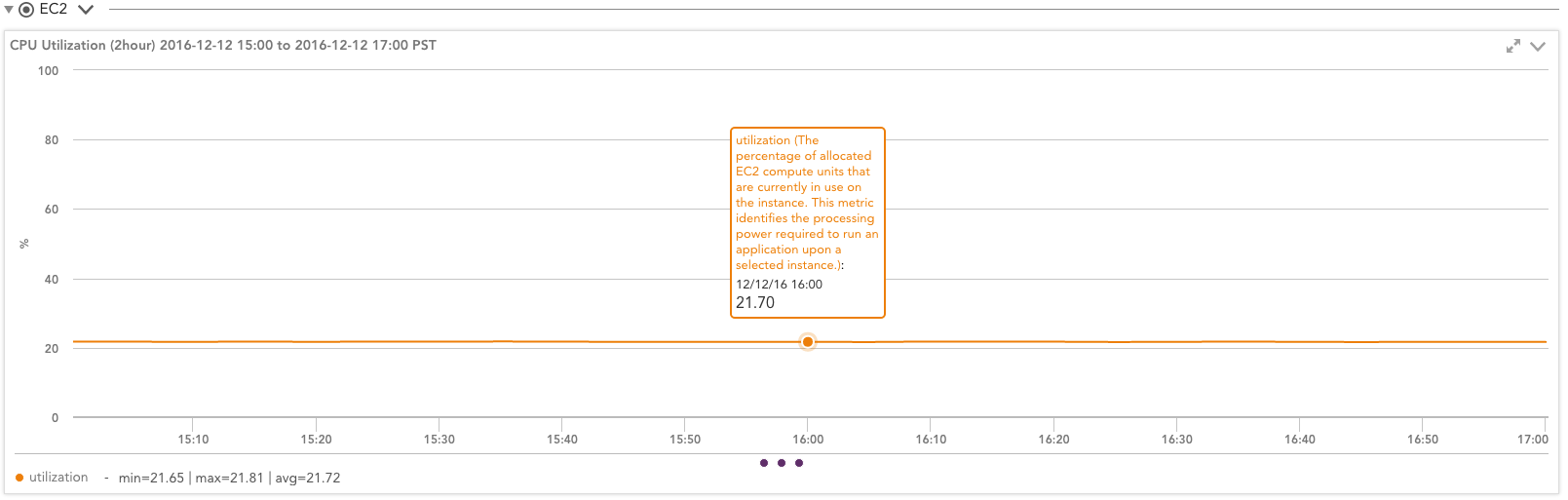
このインスタンスは、0.43分あたり25.8 CPUクレジットを消費しています(一定の残高がゼロであるため、割り当てられた速度ですべてのクレジットを消費しています)。 したがって、実際には、このインスタンスは、理論上の43ではなく、60時間あたり24の使用クレジット(.XNUMX * XNUMX分)を取得しています。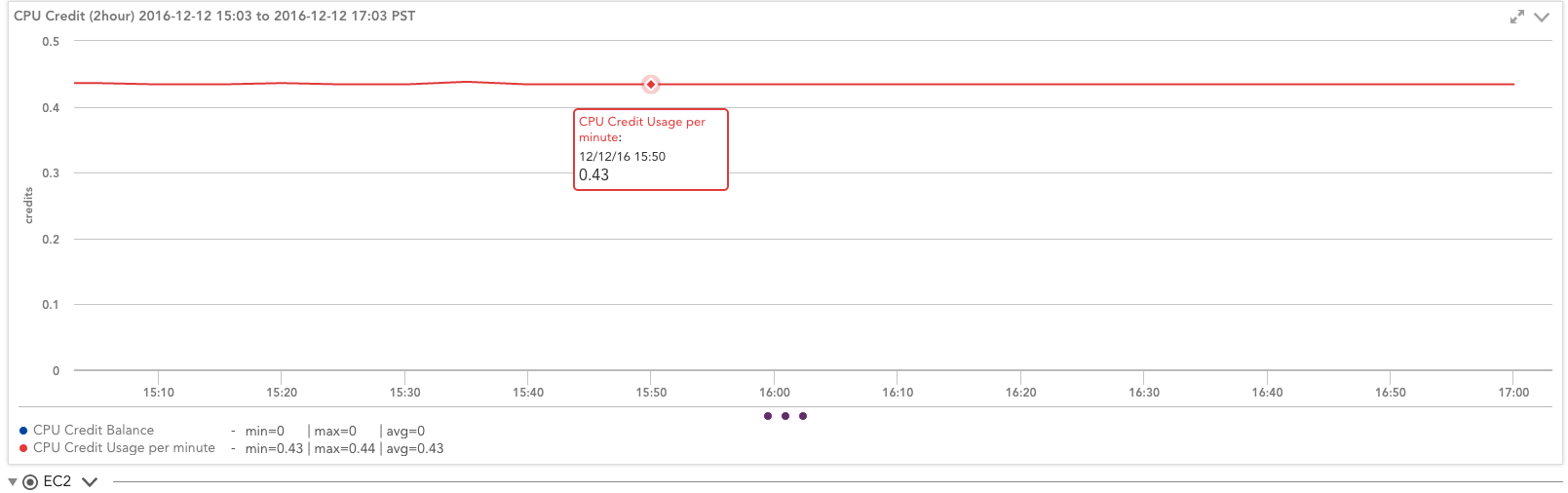
しかし、これはインスタンスのパフォーマンスにどのような意味がありますか? Amazonは、インスタンスが21%の使用率で実行されていると考えています(CloudWatchの報告による)。 オペレーティングシステムはどう思いますか?
同じインスタンスのオペレーティングシステムのパフォーマンス統計を見ると、非常に異なる状況がわかります。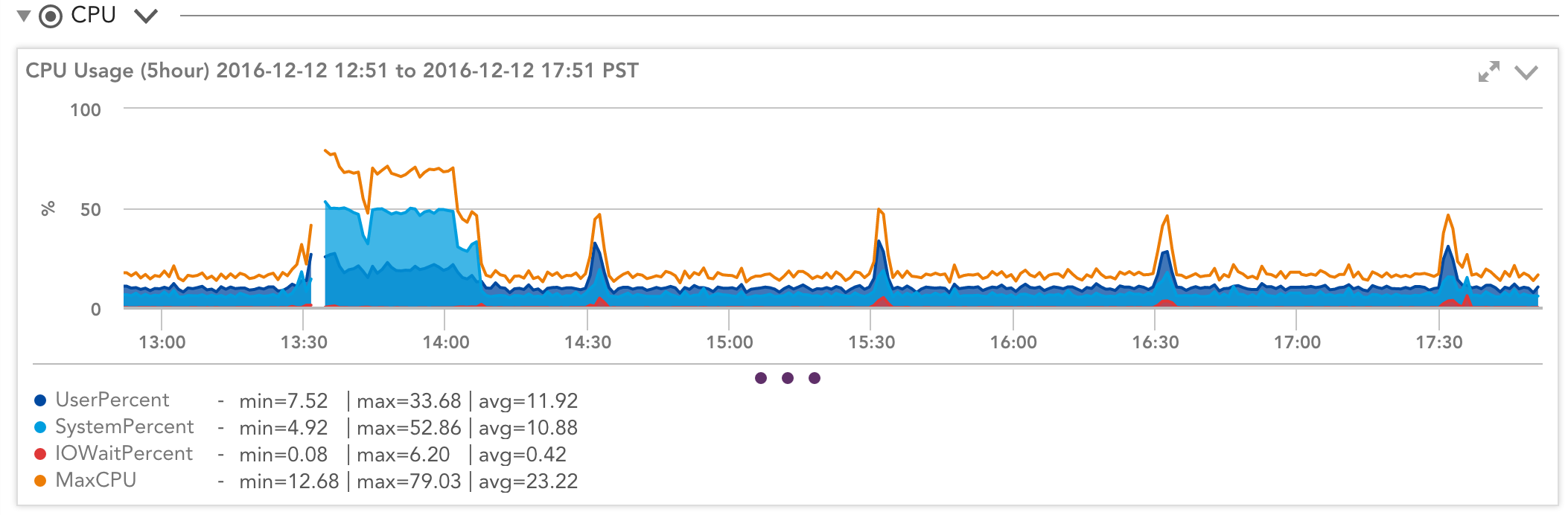
CloudWatchの使用率が示すものにもかかわらず、使用率は一定ではなく、ピークと持続的な負荷でジャンプします。 21つを調整する方法は? CloudWatchによると、システムは、オペレーティングシステムごとに12%で実行されている場合、使用可能なノードリソースの21%を使用し、オペレーティングシステムごとに80%で実行されている場合もXNUMX%を使用しています。 え?
物事を少し違った考え方にするのに役立ちます。 21%は、「CPUクレジットによって課せられた現在の制約内で実行できる合計作業」と考えてください。 これを毎秒21ワークユニットと呼びましょう。 オペレーティングシステムはこの制約を認識していないため、21のワークユニットで実行できる合計作業をOSに実行するように要求すると、1秒で完了し、アイドル状態になります。 より多くの作業があれば、より多くの作業を実行できたと考えられます。つまり、59秒間ビジー、次の1.6秒間アイドル、または98%ビジーであると報告されます。 ただし、これは、コンピューターが最初の42秒間に2%多くの作業を実行できたという意味ではないことに注意してください。 コンピューターにXNUMXの作業単位を実行するように依頼すると、それを解約するのにXNUMX秒かかるため、OSに多くのアイドルCPUパワーがあるように見えても、タスクを完了するまでの待ち時間はXNUMX倍になります。
これは単純なベンチマークで確認できます。同じワークロードが与えられた2つの同一のTXNUMX.mediumインスタンスでは、同じ作業を完了するのに非常に異なる時間が表示されます。 CPUクレジットが豊富なものは、sysbenchテストをはるかに迅速に完了します。
sysbench --test = cpu --cpu-max-prime = 2000 run sysbench 0.4.12:マルチスレッドシステム評価ベンチマーク スレッド数:1 CPUテストでチェックされた最大プライム数:2000 テスト実行の概要: 合計時間:1.3148秒 イベントの総数:10000
同一のインスタンスですが、CPUクレジットがゼロの場合、同じ作業を行うのにはるかに長い時間がかかります。
テスト実行の概要: 合計時間:9.5517秒 イベントの総数:10000
どちらのシステムも、OSレベルから50%のCPU負荷(100%で実行されているデュアルコアシステムのシングルコア)を報告しました。 しかし、それらは同一の「ハードウェア」であるにもかかわらず、同じ作業を行うのに非常に異なる時間を要しました。
事実上、これはCPUが「ビジー」である可能性があるが、何の作業も行わないことを意味します(クレジットが不足していて、その時点で基本割り当てを使用している場合)。 これは、VMware環境の「CPUReady」カウンターに非常に類似しているようです。これは、ゲストOSに実行する作業があったが、CPUにそれを実行するようにスケジュールできなかったことを示します。 つまり、「アイドル」および「ビジー」のCPUパフォーマンスメトリックは、CPUクレジットが不足している場合、次の能力を示すものではありません。 より多くの仕事をする –代わりに、それらは能力の指標です プロセッサキューにより多くの作業を配置します。 そしてもちろん、キューに多くのものがあると、待ち時間が長くなります。
したがって、明らかにCPUクレジットに注意を払う必要があります。 LogicMonitorを使用している場合は、簡単に実行できます。T2インスタンスクレジットデータソースがこれを自動的に実行します。 (これはすでにアカウントにあるか、コアリポジトリからインポートできます。)このデータソースは、CPUクレジット残高とそれらが消費されているレートをプロットするため、次のコンテキストでクレジットの動作を簡単に確認できます。 OSとCloudWatchの統計:
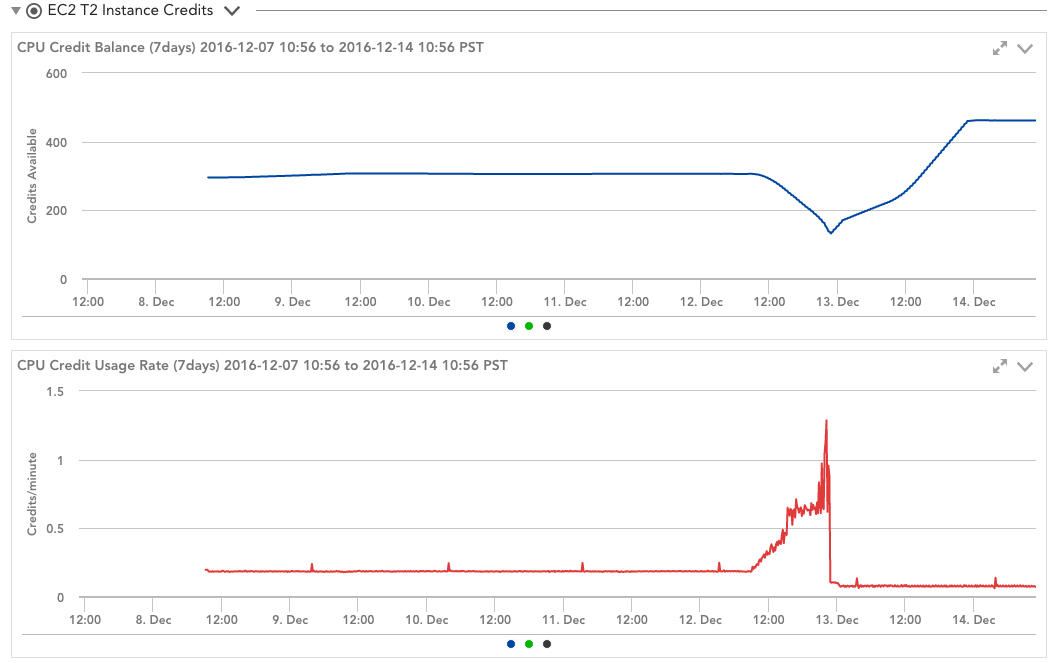
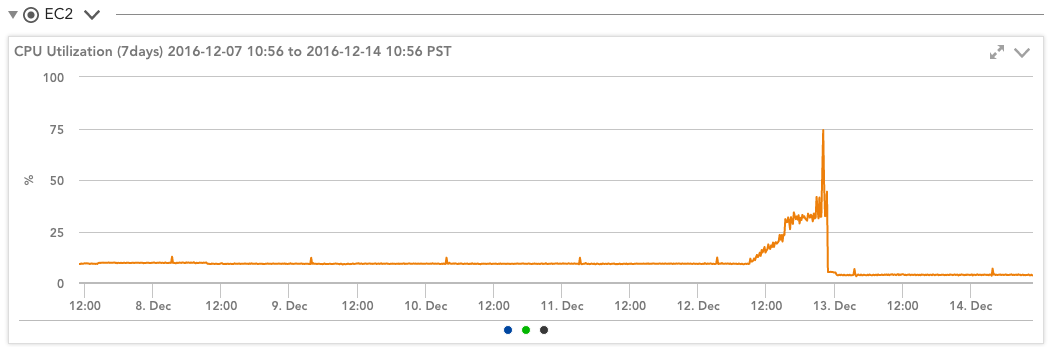
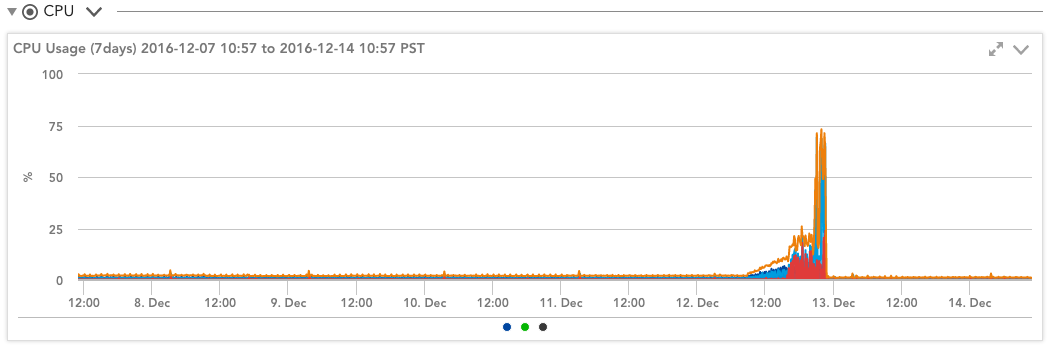
このデータソースは、インスタンスのCPUクレジットが不足したときにも警告するため、見かけのCPU使用率の突然の急上昇が、Amazonによる抑制によるものなのか、実際のワークロードの増加によるものなのかがわかります。
しかし、CPUクレジットが不足しているというアラートを受け取った場合はどうしますか? それは重要ですか? まあ、ほとんどのもののように-それは異なります。 インスタンスが遅延の影響を受けやすいアプリケーションに使用されている場合、これは絶対に重要です。これは、CPU容量が減少し、タスクがキューに入れられ、CPUがアイドル状態であることは、未使用の容量がなくなったことを意味します。 一部のアプリケーションでは、これで問題ありません。 一部の人にとっては、エンドユーザーエクスペリエンスを台無しにするでしょう。 そのため、CloudWatchデータ、OSレベルのデータ、アプリケーションのパフォーマンスなど、システムのすべての側面を監視できる監視システムを用意することが重要です。
もう2つの注意:T2インスタンスは、メモリXNUMXGBあたりの最も安価なインスタンスタイプです。 メモリが必要であるが、ベースラインのCPUパフォーマンスを処理できる場合は、常にすべてのCPUクレジットを消費している場合でも、TXNUMXインスタンスを実行するのが妥当な選択です。
うまくいけば、それはあなたのCPUクレジットを使い果たすことの現実世界の効果の有用な内訳でした。
もっと見たいです? ここで私たちに従ってください:
または、@メールでお問い合わせください [メール保護]