
組織は、イノベーションを加速し、市場の変化によりよく対応し、よりスマートに仕事をするというプレッシャーにさらされています。 DevOps に必要な継続的デリバリーと俊敏性を強化するために、あらゆる業界のあらゆる規模の企業がクラウドを採用しています。 最近の調査では、参加者の 92% が複数のクラウド ベンダーを使用していました。
クラウド ソリューションには大きな利点がありますが、多くの組織は、コスト、セキュリティ、コンプライアンス、およびその他の懸念から、依然として主要なサービスとアプリをオンプレミスに維持しています。 彼らは、統合レイヤーとして、オンプレミスとクラウドの両方で実行できるコンテナー化されたアプリケーションを採用しています。
コンテナのメリットを最大限に活用する
大規模なコンテナーでアプリケーションを実行する ハイブリッドクラウド環境 複雑です。 コンテナーの複数のクラスターを管理し、適切なワークロードが適切な場所で実行されていることを確認する必要があります。 このため、コンテナーを使用するほとんどの組織は、Kubernetes などのオーケストレーション ツールも採用しています。
Kubernetes を使用する場合、組織は、コンテナーで実行されているアプリケーションのパフォーマンスだけでなく、基盤となる Kubernetes リソースとオーケストレーション コンポーネントの正常性を把握する必要があります。 展開を最大限に活用するには、この洞察を組織の既存の監視対象ハイブリッド インフラストラクチャと共に単一のプラットフォームで提示する必要があります。
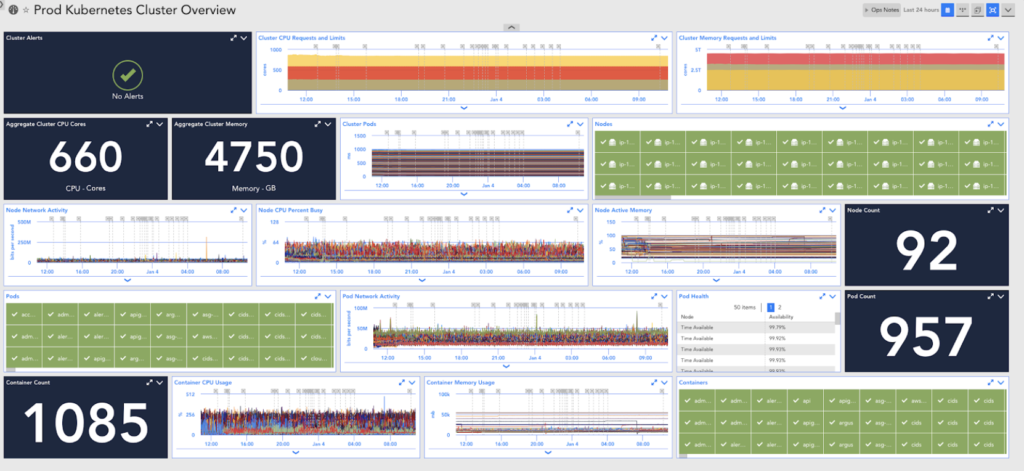
ヒント #1: Kubernetes は、マスターワーカー、ノードベースのクラスター アーキテクチャに従います。 これらのノード、およびこれらのノードで実行される Kubernetes ポッドとコンテナーを監視すると、Kubernetes で実行されるアプリケーションの基盤となるインフラストラクチャについての洞察を得ることができます。
Kubernetes ノードのモニタリング
Kubernetes マスターはワークロードをスケジュールします。 ワーカーノード、環境に応じて、物理サーバーまたは仮想マシンにすることができます。 従来の鍵サーバーに加えて、 VM 指標組織は、各ノードに割り当て可能な CPU とメモリ、およびノードの CPU とメモリの制限 (必要なリソース) と要求 (要求されたリソース) を監視する必要があります。 . これらのメトリックを監視すると、クラスタ リソースとアプリケーションを最適化できる場所を特定するのに役立ちます。
Kubernetes ポッドのモニタリング
Kubernetes の基本単位は、Kubernetes ノード上で実行され、XNUMX つ以上のコンテナーで構成されるポッドです。. ポッドを監視して、ポッドの準備ができているかどうか、ヘルス チェックに合格しているかどうか、ポッドが使用している CPU とメモリの量、ネットワーク スループットを把握することで、クラスターの一般的な正常性を把握できます。
コンテナの監視
Pod を監視すると、Pod に関する情報も提供されます。 コンテナ. Pod 内のコンテナーは、集合的に最終目標を達成する作業の単位です。 コンテナーの CPU 使用率、メモリ使用率、再起動回数などのメトリックを取得すると、根本原因とパフォーマンスのボトルネックを特定するのに役立ちます。 さらに、組織は、コンテナーで実行されているアプリケーションに固有の主要なメトリックを監視し、アラートを出す必要があります。
今は見える…今は見えない
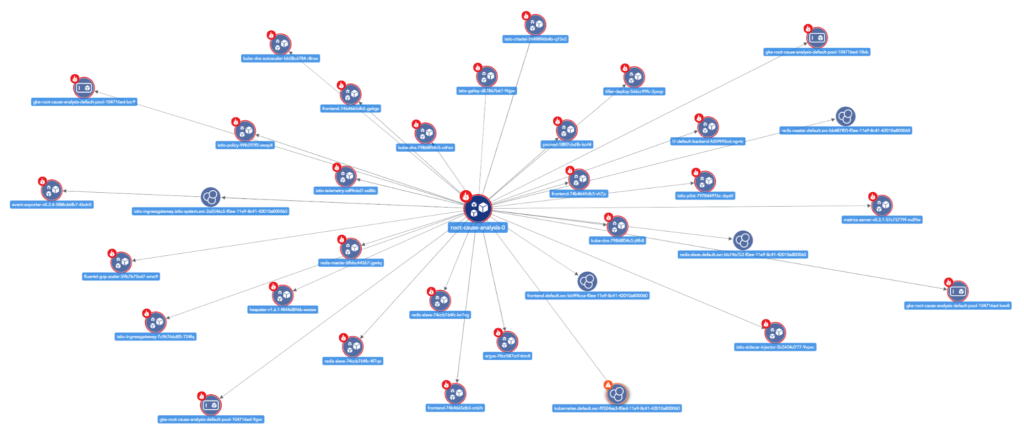
Kubernetes コンテナーとポッドは一時的なリソースです。 すぐに予期せず出現 (および消滅) する可能性のあるコンポーネントを監視することは困難です。 また、タイムリーに監視対象に追加および削除することも困難です。 新しいリソースを定期的にチェックすることに依存する従来の検出システムでは、変更を迅速に取得できない場合があります。
ヒント #2: エフェメラル リソースを正確に追跡するには、 イベントベースの発見、ここでは、Kubernetes イベントに基づいて、クラスター リソースが監視対象から自動的に追加および削除されます。
どこで何が起きている?
基盤となるリソースが一時的なものである場合、サービスとアプリケーションの全体的な正常性とパフォーマンスを判断することは必ずしも容易ではありません。
ヒント 3: 個々の一時的なインスタンスに注目するのではなく、共通のサービスまたはアプリケーションをサポートするリソースを論理的にグループ化し、サービスまたはアプリケーション全体の主要業績評価指標の集計を監視します。
モニタリングへのアプローチを改善する時が来ました
今日のハイブリッド クラウド環境と革新的なコンテナ テクノロジが、IT に新たな課題をもたらしていることは明らかです。 しかし、監視への適切なアプローチにより、組織は、最も重要なアプリやサービスの正常性とパフォーマンスを維持するために必要な可視性と洞察を得ることができます。 S14 日間の無料トライアルにサインアップする. 始める方法をお見せしましょう。