

今日の企業は、デジタルトランスフォーメーションを採用し、インフラストラクチャを最新化して、製品をより迅速に提供し、競合他社に先んじています。 ここLogicMonitorでは、通常、この近代化の結果を、企業がコストやセキュリティなどの要素を最適化しながら、より高速に拡張および展開できるという利点を実現できる分散型のハイブリッドITインフラストラクチャと見なしています。 ただし、この最新のハイブリッドインフラストラクチャは、監視に関する考え方を変え、従来のほとんどの監視製品では、包括的な監視を実現するにはもはや十分ではありません。 包括的な監視がないと、企業は高額なダウンタイムのリスクを負います。 このダウンタイムを回避するためにできる限りのことを行っていますが、実際には、企業はほとんどの時間を問題への対応に費やしています。 現代の企業は、問題が発生する前に警告し、問題に対応するのではなく、問題を防ぐのに役立つ何かを必要としています。 LogicMonitorでは、これがまさにAIOps早期警告システムで構築しているものです。
クラウドおよびオンプレミスでの早期警告
最新のハイブリッドインフラストラクチャには、通常、クラウド内のリソースと、物理データセンターのオンプレミスで実行されている他のリソースが混在しています。 これらの多くの場合、アプリケーションはコンテナーで実行され、環境全体でのアプリケーション管理とデプロイメントを標準化します。 繰り返しになりますが、この組み合わせにより、企業は両方の長所を活用でき、コスト、セキュリティ、スケーラビリティ、展開速度などを微調整できますが、監視ははるかに複雑になります。 利用可能なほとんどの監視製品は、XNUMXつのタイプのインフラストラクチャのみの監視に特化しています(マシン情報の記入> という構文でなければなりません。例えば、 or オンプレミスインフラストラクチャ)、その結果、企業は複数の監視プラットフォームを使用し、フルタイムのスタッフでさえ、これらの監視プラットフォームから出力される膨大な量の構成とデータの管理に専念しています。 もちろん、彼らはあらゆる犠牲を払ってダウンタイムを防止しようとしていますが、現実には、これらのアプローチはスケーラブルではなく、通常、IT運用は問題への対応にすべての時間を費やし、結果として生じるダウンタイムを最小限に抑えようとします。
潜在的なダウンタイムを防ぐ
ダウンタイムは高額であり、会社のコストを最大XNUMX倍まで押し上げます。 最近の調査 ダウンタイムが横行していることを明らかにし、回答したIT意思決定者の96%が、過去51年間に少なくともXNUMX回の大規模な停止を報告しました。 同じ調査によると、これらの停止のXNUMX%は回避可能でした。 しかし、大部分の時間が火を消すために費やされている場合、IT運用チームには、影響を最小限に抑えるのではなく、停止を回避することに重点を置いたプロアクティブなモデルに切り替える時間やリソースがありません。 LogicMonitorのAIOps早期警告システムは、IT運用者に、問題に対応するのではなく、問題を予防的に防止するための切り替えを行うために必要な情報を提供します。
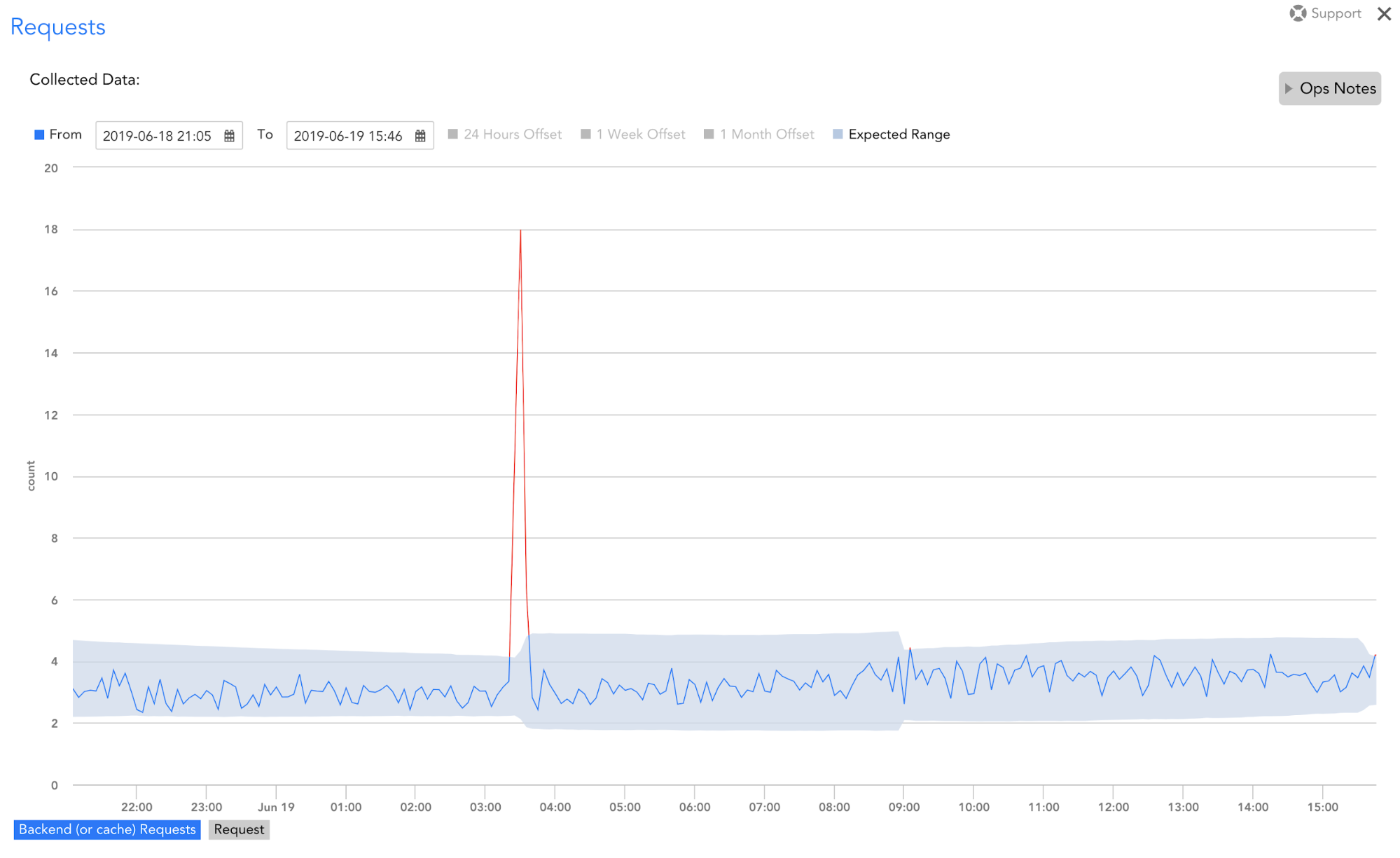
具体的には、LogicMonitorのAIOps早期警告システムは、アラートやパフォーマンスデータのパターンや異常などの問題に先行する警告の兆候や症状を検出し、それに応じてユーザーに警告します。 これらの早期警告により、統合やカスタムスクリプトなどのアクションをトリガーして、問題の発生を防ぐことができます。 この早期警告システムは、ユーザーに早期に警告することで、企業が停止を防ぎ、時間とお金を節約し、ブランドへの悪影響を回避するのに役立ちます。 人工知能(AI)と機械学習(ML)ベースのアルゴリズムを使用して、問題に先行する警告の兆候と症状を検出します。これは、医師が(未治療の場合)大きな病気につながる可能性のある症状を特定する方法と同様です。 これらのアルゴリズムは、監視業界で次のように知られているものに現れます。 IT運用のための人工知能(AIOps) –異常検出、動的しきい値、根本原因分析、相関などのベースの機能。 一緒に、LogicMonitorの早期警告システムの基礎となるこれらの機能は、ノイズからの信号をインテリジェントに識別して最も重要な情報を表面化し、コンテキストを追加することでこれをより実用的にし、その後、堅牢な自動化フレームワークに結び付けることで障害を防ぎ、チームが平均時間を大幅に改善するのを支援します修復(MTTR)し、ダウンタイムを正常に防止します。
この早期警報システムは、 LogicMonitorの既存のハイブリッドインフラストラクチャ監視プラットフォーム IT運用チームが問題を防止しながら時間を節約できるようにする たったXNUMXつのプラットフォーム。 LogicMonitorの幅広いカバレッジ。2000を超えるすぐに使用できるモニタリングテンプレートが、クラウドから従来のオンプレミス環境にあるシステムまで、あらゆるものをカバーします(マシン情報の記入> という構文でなければなりません。例えば、 サーバー、スイッチ、ストレージアレイなど)からコンテナおよびその中で実行されているアプリケーションは、比類のないものです。 この包括的なカバレッジにより、早期警告システムは、複雑で分散した最新のITインフラストラクチャ全体にわたる問題を特定して防止することができます。 さらに、LogicMonitorの組み込みの自動化と事前構成されたデフォルト(マシン情報の記入> という構文でなければなりません。例えば、 アラートしきい値)は、ドメイン固有のベストプラクティスに基づいており、チームがイノベーションに費やす時間を増やし、監視の管理に費やす時間を減らすことができます。
デジタルトランスフォーメーションを実施している現代の企業は、従来の監視によって速度を落とし、デジタルトランスフォーメーションがもたらすメリットを完全に実現できないようにする余裕がありません。 これらの企業は、LogicMonitorの早期警告システムなど、複雑で分散したインフラストラクチャ全体の障害を防ぐのに十分なインテリジェントな監視を必要としています。

