
LogicMonitorは、成長を続けるAIOps機能に加えて、異常の視覚化を発表できることを誇りに思います。 この新機能により、ユーザーは監視対象のリソースで発生する異常を視覚化し、その異常を過去24時間、7日、30日などの主要な履歴信号と比較できます。 異常の視覚化は、LogicMonitorの既存の視覚化を補完します 予報 機能性を備え、リソースの状態をよりよく理解するためのインテリジェンスの別のレイヤーを提供します。 異常をすばやく特定する機能により、LogicMonitorユーザーはより迅速かつ効果的にトラブルシューティングを行うことができます。
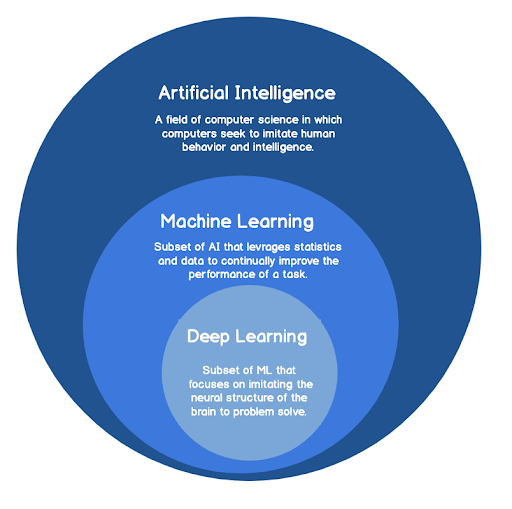
異常検出がIT運用またはAIOpsの人工知能(AI)のどこに適合するかを最初に理解することが重要です。 AIは、コンピューターが膨大な知識と人間に危害を加える特権を持っているという抽象的な概念として描かれることがよくあります。 この描写の一部は真実ですが、AIが動作する現実よりも優れたハリウッド映画(iRobotは誰ですか?)になります。 AIは、機械で人間的な行動を模倣することを目的としたコンピュータサイエンスの幅広い分野です。 人工知能、機械学習、深層学習の関係を図1に示します。ここで、機械学習はAIのサブセットであり、深層学習は機械学習のサブセットです。 AIは、IT運用に関連しているため、一般的に機械学習の形をとります。 異常検出、アラートクラスタリング、パターン分析などの機能はすべて、機械学習の例です。 より一般的には、これらは機能またはタスクであり、データ量が増えるとパフォーマンスが向上します。
異常検出は、データセット内の偏差または異常を識別します。 ITでは、これは通常、特定のメトリックの異常なスパイクを理解する機能に変換されます(マシン情報の記入> という構文でなければなりません。例えば、 CPU使用率、ネットワークスループット、遅延など)。 チームは、従来の静的しきい値で設定された制限内で発生する異常を特定することで、重大な可能性のあるイベントを発生前にキャッチし、ダウンタイムを防ぐことができます。 LogicMonitorのサイト信頼性エンジニアリング(SRE)チームは、異常検出を使用してこれを実行しました。 ある日、タスクキューで送信メッセージが劇的に減少しました。これを未解決のままにすると、LogicMonitorアプリケーションの特定の機能のアクセシビリティに影響を与える可能性があります(これは良くありません!)。
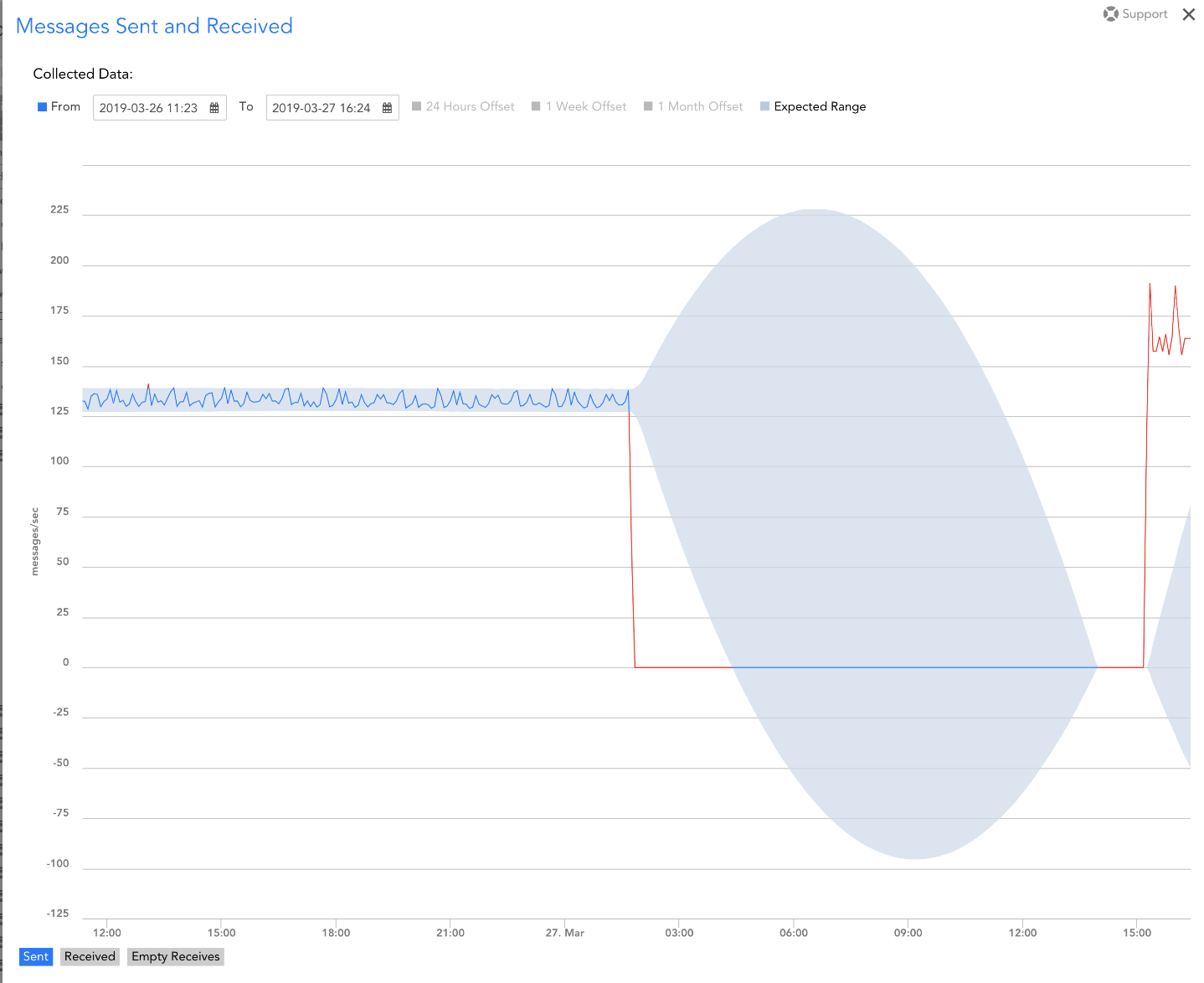
インフラストラクチャの変更により、送信されるメッセージは約125メッセージからゼロに劇的に減少しました。 この劇的な減少は、標準のアラートしきい値によってキャッチされなかったため、アラートをトリガーしませんでした(これをキャッチするために、送信されたメッセージがゼロのときにキャッチするようにアラートしきい値を設定できましたが、常にアラート可能な状態であるとは限りません) 。
LogicMonitorの新しい異常検出機能により、LogicMonitor SREチームはドロップを識別し、OpsNoteでタグ付けすることができました。 この異常を視覚的に識別する機能により、トラブルシューティングワークフローが促進され、LogicMonitorアプリケーションの稼働時間と可用性を最大化できるようになりました。
異常の視覚化は、シナリオのトラブルシューティングに役立つインテリジェンスの別のレイヤーを提供します。 リソースが時間の経過とともにどのように実行されたかを理解することで、ユーザーはリソースのベースラインヘルスを理解できます。これは、容量の計画と長期的な季節的傾向の決定に役立ちます。 これらのテナントは両方とも組み合わされて、トラブルシューティング時にユーザーがより多くの情報に基づいた意思決定を行えるようにします。これにより、最終的にエンドユーザーのダウンタイムが短縮され、サービスSLAへの準拠が向上します。
ポータルでこの機能にアクセスするには、を参照してください。 このサポートガイド 開始方法に関するドキュメント。 実際の動作を確認したい場合は、カスタマーサクセスマネージャーまたは営業担当者に詳細をお問い合わせください。

