
で 以前の投稿、私はAIOpsの可能性と、真のAI(人工知能)がまだ監視スペースにあまり影響を与えていない理由について話しました。 しかし、私は信じています アルゴリズム的 IT運用は、LogicMonitorがこの投稿でそこにたどり着くまでの道のりを支援し、共有します。
データセンターを運営していたとき、監視の主な課題は、収集するデータを知ることでした(CPU、メモリ使用量、ネットワークなどのメトリックを収集するだけでは、問題について警告したりトラブルシューティングしたりするのに十分ではないことを、ハードな経験から学びました)。 警告するように設定するしきい値。 また、すべてのデータを大規模に保存、処理、視覚化、警告する方法。
LogicMonitorは、最大2年間、すべてのサンプルを損失なく保存する非常にスケーラブルなTSDBを使用して、お客様のこれらの問題を解決するという素晴らしい仕事をしてきました。 1,500を超える監視統合のライブラリ ベストプラクティスのアラートしきい値が定義されているなど。 しかし、監視の問題は変化しました。
サーバー上で実行されているアプリケーションや、データベースと通信するWebサーバーの小さなセットによってユーザーエクスペリエンスが定義されることはなくなりました。 今日、ユーザーエクスペリエンスは、パブリッククラウド環境とプライベートデータセンター環境に分散されたさまざまなマイクロサービスとアプリケーションに依存する可能性があります。 (クラウドアプリの約90%は、オンプレミスアプリケーションとデータを共有します。)
そのため、LogicMonitorは、これらのハイブリッドおよびクラウド展開に対する独自の洞察を提供し、多くのデータと実用的なアラートをすぐに提供できますが、これは過剰なアラートにつながる可能性があります。 共有サービスまたは主要なネットワークコンポーネントの問題は、多くの依存アプリケーションでアラートを引き起こす可能性があり、すべてシステムの状態を正確に反映しているものの、問題の修正が遅くなる可能性があります。
私たちの目標は、ユーザーの仕事をより良くすることです。 ITの問題を可能な限り迅速に予測、防止、解決するため。 この目的のために、私たちはAIOpsを使用した超効率的なアラートに向けて取り組んでいます。 そこにたどり着くのに役立つ一連の機能を展開します。
トポロジーの発見と視覚化
間もなく、LogicMonitorは、トポロジ情報を自動的に検出して提示できるようになります。ネットワーク(スイッチとルーター)レベル、およびクラウド環境とデータセンター環境の両方のアプリケーションレベル(トラフィックフローに基づく)で、仮想マシンのマッピングにまで拡張されます。データストアと物理ストレージリソースに。 この発見されたコンテキストは、複数のタイプの関係と依存関係を理解しており、アプリケーションの「モデル」です。 これはそれ自体で非常に便利ですが、以下で説明する他のAIOps機能や高度なIT管理機能の一部を有効にするためにも不可欠です。 したがって、メタであるために、「依存関係」は残りのAIOpsの依存関係です。
サービスの定義と監視
管理者は、サービスまたはアプリケーションをコンポーネント(コンテナー、仮想マシン、データベース、ストレージアレイ、ロードバランサーなど)のコレクションとして定義し、そのサービス全体でSLA、スケジュールされたダウンタイムなどを定義できます。 アラートは、サービスのコンポーネントの集計メトリックに対して設定できます(たとえば、コンテナーが負荷に応じてスケールアップおよびスケールダウンする場合でも、サービス内のコンテナーによって処理される要求の最大および平均レイテンシー)。 これにより、管理者と開発者はサービスを一貫して管理できます。 重要なことに、これにより、監視システムはサービスに関するコンテキストを持つことができます。「サービスXはこれらの構成要素で構成されます」(一部は他のサービスである可能性があります)。 これは、間もなく登場する他の機能でも不可欠になります。 また、アラートを大幅に削減し、非常に効率的なアラートに移行できます。 サービス内のサーバーの一部がダウンしているが、サービス全体の遅延が問題ない場合、管理者は心配したり警告したりする必要はありません。 そのため、エスカレーションされたアラートは、ユーザーが関心を持っているサービスレベルのアラートのみに制限できます。
アラートの依存関係
この場合も、トポロジと依存関係の情報を使用して、LogicMonitorは依存システムからのアラートを自動的に抑制し、真の根本原因の可能性のある候補を強調表示することを目的としています。 状態の単一の一意のアラートをルートとして識別することは不可能かもしれませんが、そうでなければ数百のアラートである可能性があるものを少数の重要な候補に減らすことは可能です。
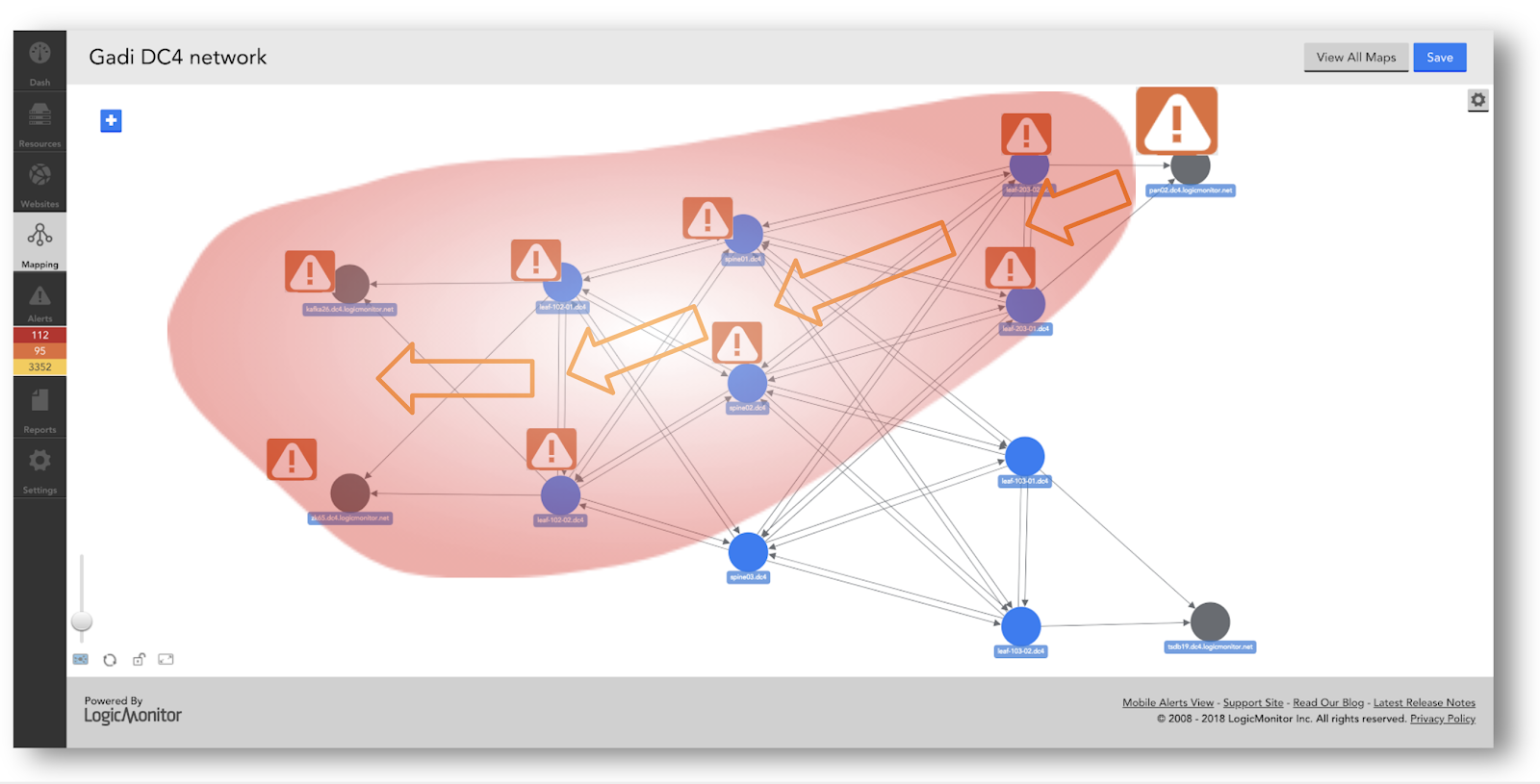
異常の検出と警告自体は、有用な機能としての機能の点で制限されています。 仮想マシンのCPU負荷が20%から40%に跳ね上がる場合、それは異常である可能性がありますが、60%の空き容量があることを考えると、ユーザーへの影響はありません。 このようなすべての異常を調査するためのリソースを持っている企業はほとんどないため、このようなアラートは運用チームにアラートを無視するように指示します。 チームが前兆の問題を調査するためのリソースが不足している場合は、ベストプラクティスのしきい値に依存する方がよい場合があります(たとえば、簡単な例では、CPUが90分以上で4%を超えています)。 依存関係の問題に対処しない場合、異常検出も問題になります。システムAがシステムBに依存し、システムBの動作が遅くなると、システムAは異常に動作し、役に立たないアラートをトリガーします。
ただし、異常検出は場合によっては非常に役立つことがあります。 サービスのトポロジと依存関係がシステムによって十分に理解されている場合、依存しているコンポーネントの異常な動作は、アラートがない場合でも、考えられる根本原因として強調表示できます。 逆に、メトリックが 異常を調査ビューから除外して、解決までの時間を大幅に短縮できます(特に、違いが通常の毎週繰り返されるサイクルであるにもかかわらず、メトリックが異常に見える場合は特に)。
では、「超効率」の部分はどこにあるのでしょうか。
ここで観察することが本当に重要なことがあります。 依存関係によってトリガーされるアラートを抑制することは非常に重要です。 これは、お客様からの最も一般的なリクエストのXNUMXつです。 異常によって引き起こされるアラートも興味深いものであり、多くのベンダーがそれらを実装し始めています。
ただし…これは、アラートの世界がどのように見えるかです。
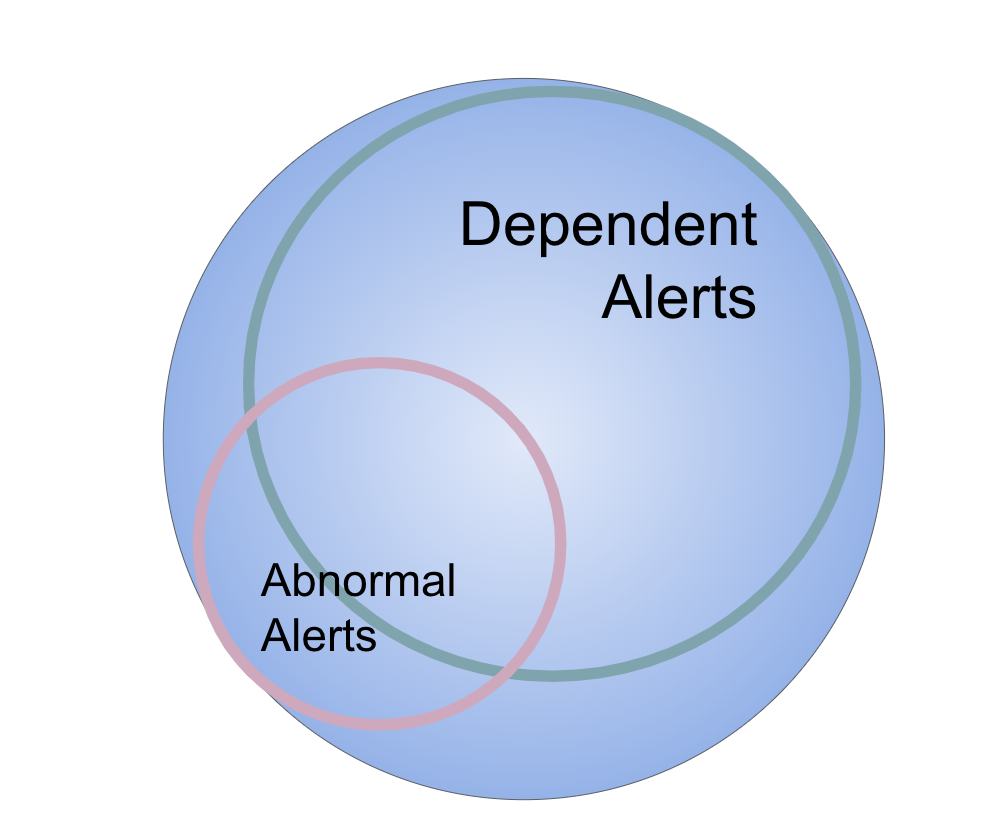
依存関係の結果としてアラートが発生すると、異常アラートもトリガーされます。 したがって、対処する必要のある大きな重複があります。 依存関係に基づくアラートを理解して管理することは、最初に行う必要があることだと考えています。 これを行わないベンダーは、大量の誤検知異常アラート(!)を生成します。 一緒に行われた場合にのみ、システムは実際にノイズを低減し、興味深いアラートを提供できます。
依存アラートの原因または実際の異常である異常アラートのいずれか。 LogicMonitorは、トポロジ依存関係情報を使用して、依存関係がアラートになっているシステムによってトリガーされる異常アラートを抑制します。
コスト最適化
パブリッククラウドプロバイダーが展開しているオプションの範囲が拡大し続けているため、リソースを浪費するのは簡単です(これはお金の浪費につながります)。 接続されていないストレージボリュームのように、まだ支払いが行われているという明らかなケースがあります。 何ヶ月もアイドル状態になっているインスタンスを計算します。 過剰にプロビジョニングされたストレージまたはコンピューティング。 ただし、運用スタッフがアプリケーションをデプロイするときにリソースのサイズを正しく設定したとしても、時間の経過に伴うアプリケーションの使用状況と、アプリケーションの実行に使用できるインスタンスとストレージの種類の両方が変化します。 AIOpsは、季節性や周期性を考慮した、予想される使用状況を示すモデルを使用し、それをクラウドプロバイダーの提供内容の継続的な更新と組み合わせることで、アプリケーションに最適なリソースを自動的に推奨します。 これをプロビジョニングツールと統合して、再構成を自動化できます。 変更によるコストの劇的な増加、または節約の劇的な機会を警告するアラートは、ほとんどの請求最適化プロセスが実行される月末まで待つ必要はありません。
相関
システムまたはサービスのトラブルシューティングを行うときは、同様の動作をしている他のシステムがあったかどうかを知ることが役立つことがよくあります。 LogicMonitorは、アラートのメトリックと相関している、他のトポロジ的に関連するシステムのメトリックを表示できるようにすることを目的としています。これは原因となる可能性があります。 これは、トポロジ情報に依存するもうXNUMXつの機能です。 何万ものデバイスを監視しているアカウントでは、いくつかのランダムなシステムで、原因ではないが強く相関するメトリックが存在することがほぼ保証されています。 相関についてスキャンされたメトリックをトポロジ的に関連するメトリックに制限することは、結果が単なる疑似ではなく、興味深い相関である可能性が高いことを意味します。 ((疑似相関 は素晴らしいサイトであり、次のような興味深い事実を発見することができます 「ベッドから落ちて亡くなった人」は「ワシントンDCの弁護士の数」と相関関係があります)。 注意すべきもうXNUMXつの要素は、相関するメトリックのセットがトポロジデータによって制限されない限り、大規模でタイムリーに多変量相関を実行する方法がないことです。 組み合わせセットは大きすぎて、ビッグデータテクノロジーであっても、リアルタイムに近いものを処理することはできません。
ホリスティックモニタリング
他のシステム(Kubernetes、コストシステム、GCP、CI / CDシステムなど)との統合から得られた情報を使用して、LogicMonitorは動作の変化におけるより大きな重要性を推測できるようになります。 たとえば、一部のコンテナが破棄され、新しいコンテナがソフトウェアリリースの一部として展開された後、アプリケーションサービスのパフォーマンス特性が異なる場合、それを強調表示して開発者の注意を引くことができます。 (「ソフトウェアの新しいリリースでは、以前のリリースよりも90%多くのデータベースクエリが必要です。これにより、AWSで同じレベルのパフォーマンスを維持するには、年間20,000ドルの追加費用がかかります。」)
これは、LogicMonitorが間もなくリリースするために積極的に取り組んでいるいくつかのAIOps機能の前兆です。 ここでの目的は、私たちが向かっている場所のプレビューを提供し、これらのAIOps機能のいくつかが絡み合っていることを伝えることです。 戦略的なAIOpsの展開を計画せずに、2019つの機能(異常検出など)をリリースするだけで、チームがより悪い状況に陥る可能性があります。 したがって、これは、AIOps機能の一部が私たちが望むよりも少し時間がかかることを意味するかもしれませんが、待つ価値があります! XNUMX年前半を楽しみにしています。