

LogicMonitorでは、主に大量の時系列データを扱います。 お客様のデバイスは定期的に監視され、データポイントがエージェントレスアプリケーションに提供されて処理および解釈されます。 最近、異常検出を強化するために、アプリケーションでの機械学習の存在を拡大するように努めました。 これには、データポイント値の連続ストリームを迅速に解釈し、意味のある異常分析を返し、潜在的な季節性を検出し、アラートノイズを抑制することができるステートレスマイクロサービスの開発が含まれていました。
ただし、このブログの目的は、異常検出マイクロサービスについて説明することではなく、Redisを中心的なフィクスチャとして含める理由を調査することです。 さらに、Redisストレージのフットプリントを削減するために採用されているさまざまな圧縮戦略と、それぞれの長所と短所について説明します。
Redisとは何ですか?
Redis(Remote Dictionary Server)は、によって開発された非常に高速なNoSQLキー値データ構造サーバーです。 Redisの ANSICプログラミング言語で書かれています。 Redisはメモリ内キャッシュを実行します。つまり、データ構造ストアは、従来のデータベースよりもはるかに迅速に保存および呼び出すことができます。 その速度に加えて、Redisは幅広い抽象を簡単にサポートすることもできます データ型、ほとんどすべての状況で非常に柔軟になります。
状態モデルの例
環境内の複数のポッドにわたってさまざまなアルゴリズムの機械学習トレーニングデータを永続化するために、JSON形式のモデルを維持しています。 このモデルは、高可用性のために一元化されたRedisクラスターにキャッシュされます。 以下は、このモデルの簡略化された例です。
| { 「resource-id-1」:{ 「モデルバージョン」:文字列、 「config-version」:int、 「最後のタイムスタンプ」:int、 「algorithm-1-training-data」:{ 「バージョン」:文字列、 「training-data-value」:List [float]、 「training-data-timestamp」:List [float]、 「パラメータ-1」:float、 「パラメータ2」:フロート }, 「algorithm-2-training-data」:{ 「バージョン」:文字列、 「training-data-value」:List [float]、 「training-data-timestamp」:List [float]、 「パラメータ-1」:float、 「パラメータ2」:フロート }, ...... } } |
圧縮戦略
LZ4圧縮
デフォルトでは、Redisは保存する値を圧縮しません(続きを読む ここ)、したがって、サイズの縮小は、最初にアプリケーション側で実行する必要があります。 手動圧縮オプションのいずれかによって達成されたストレージとネットワークスループットの節約は、追加の処理時間の価値があることがわかりました。
最初は、利用することを選択しました LZ4 その速度と既存のコードベースとの統合の容易さのため。 可逆圧縮の導入により、ストレージ全体のサイズが約39,739バイトからはるかに管理しやすい16,208バイトに即座に削減されました(60%の節約)。 これらの節約のほとんどは、モデルのキー値の統計的冗長性に起因する可能性があります。
圧縮前のノイズの低減
プロジェクトが複雑になるにつれて、より長い浮動小数点値リストを追加する必要がありました。 このため、トレーニングデータモデルのサイズはXNUMX倍以上になり、統計的な冗長性を減らし、圧縮の節約を最小限に抑えた、一見ランダムな数値データで構成されていました。 これらのfloat値はそれぞれ、XNUMX進精度が大きく(Pythonの倍精度のデフォルトのため)、文字列としてRedisに設定すると、かなり多くのバイトに変換されました。 XNUMX番目の戦略は、XNUMXつの異なるオプションを使用して小数の精度を丸めることでした。 これについては、以下で詳しく説明します。
丸めオプション1(すべての値)
- すべてのfloat値を小数点以下4桁の精度に丸めます。
丸めオプション2(5番目の変位値に基づく)
- 値が0を超える場合は、浮動小数点数を小数点以下100桁に丸めます(例:54,012.43→54,012)
- 値が1〜1の場合、浮動小数点数を小数点以下99桁に丸めます(例:12.43→12.4)。
- 値が4未満の場合は、浮動小数点値を小数点以下1桁に丸めます(例:0.4312444→0.4312)
オプション1の結果: 〜80,000バイトが〜36,000バイトに削減(55%節約)
オプション2の結果: 〜80,000バイトが〜35,000バイトに削減(56%節約)
オプション1が選択されたのは、複雑さが増したり、小数点以下の精度が低下したりすることなく、ほぼ同じレベルのメモリを節約できるためです。 また、アルゴリズムへの精度の影響を失うことは重要ではないことも確認しました。
エンコーディングによる圧縮– 85%の節約!
丸めによってRedisストレージが劇的に減少しましたが、消費量は依然として多く、アルゴリズムの計算の精度のマージンが失われました。
リストに変換する前は、浮動小数点値の配列は次のように存在します。 Numpy N次元配列(ndarray)。 これらの各配列はfloat16値に縮小され、内部ZLibコーデックを使用してBloscでエンコードされました。 Bloscはマルチスレッドを使用し、データを分割して小さなブロックに圧縮できるため、従来の圧縮方法よりもはるかに高速です。
結果の圧縮配列は、Base64でエンコードされ、次のようにデコードされます。 8ビットUnicode変換形式(UTF-8) JSONにダンプされる前。 結果として得られたRedisストレージサイズは11,383バイト(約80,000バイトから)に縮小されました。これは、LZ4のみで圧縮するか、浮動小数点の小数点以下を丸めて圧縮することで達成されたものから劇的に改善されました。
最終的に、エンコードによる圧縮は、異常検出プログラムの最後の反復に含まれる戦略でした。 85つの戦略を組み合わせると、メモリ消費量のXNUMX%が節約されました。
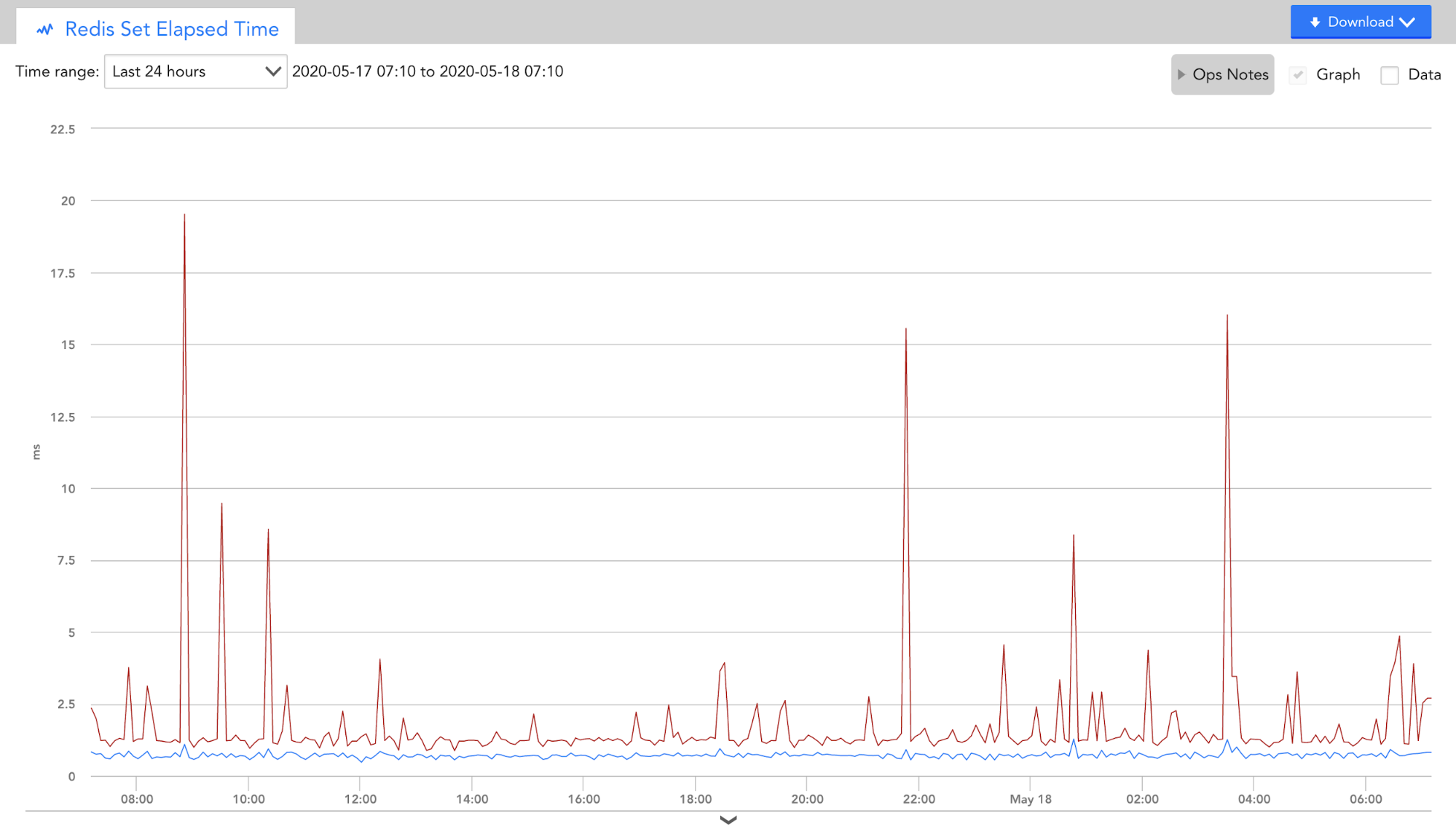
ベンチマーク中の監視
圧縮テスト中に、私たちはいくつかの すぐに使用できるRedisモジュール すべてのGetおよびSetトランザクションのパフォーマンスを監視します。 事前の圧縮がある場合とない場合の送信結果をRedisと比較すると、経過時間の大幅な改善が実証されました。
LogicMonitorについて
LogicMonitorは、エンタープライズITおよびマネージドサービスプロバイダー向けの唯一の完全に自動化されたクラウドベースのインフラストラクチャ監視プラットフォームです。。 XNUMXつの統合されたビュー内で、ネットワーク、クラウド、サーバーなどのフルスタックの可視性を獲得します。

