
先週、私はオースティンのオフィスとの間を行き来していました。つまり、読書にはかなりの時間がかかります。 他の本の中で、私は「製品開発フローの原則」、Reinertsen、Donald Gを読みました。この本の(私にとって)最も興味深い部分は、待ち行列理論の章でした。
リトルの法則は、プロセスの待機時間=キューサイズ/処理速度を示しています。 これは直感的な式ですが、幅広い適用性があります。
では、これは監視と何の関係があるのでしょうか?
システムの拡張性について過度に楽観的な推測以上のことができるようにするには、現在のパフォーマンス(サービス時間、キュー、使用率)に関するデータと、拡張性についての理解が必要です。
具体的な例として、Linuxのディスクパフォーマンスを使用してみましょう。 ディスクの待ち時間と応答時間は、多くのアプリケーションのパフォーマンスのボトルネックであるため、問題が発生する可能性がある時期を理解できることが重要です。 悪いニュース–おそらくあなたが思っているよりも早く。
洗練された順序で、スケーラビリティについて考えるときに人々がとるアプローチは次のとおりです。
1:ボトルネックにぶつかるまで、ボトルネックの調査を行わないでください。 これは驚くほど一般的なアプローチですが、お勧めするアプローチではありません。 これまでで最も重いトラフィックの間にパフォーマンス障害に対処しなければならないことは(もちろん、それらが発生するときです)、楽しいことではありません。
2:「iostat-dx」を数分間実行します。ドライブが約5%の時間ビジー状態になっていることを確認してください。問題が発生する前に、リクエストの約20倍の量を実行できると考えてください。 これは、iostatを実行したときに選択したサンプルがピークワークロードを反映していない可能性があり、キューが線形にスケーリングしないという事実を無視します(以下を参照)。

3:Linuxドライブの実際のパフォーマンスを監視およびグラフ化して、さまざまなワークロードでの時間の経過に伴うパフォーマンスを確認します。 (注:Linux SNMPエージェントは、デフォルトではディスク使用率と遅延を公開せず、 net-snmpdの拡張)。 これにより、実際のワークロードでシステムがどのように機能するかについての優れた洞察が得られます。
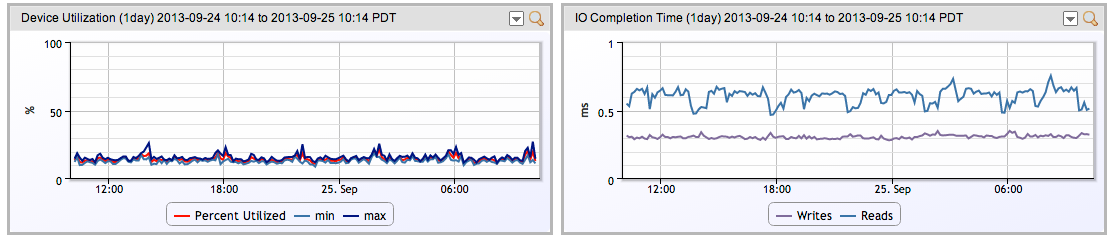
これにより、時間の経過に伴う実際のパフォーマンスが示されますが、パフォーマンスの拡張方法に関して誤解を招く可能性があります。 ただし、大きな利点は、負荷が拡大するにつれて、パフォーマンスがどのように変化するかをリアルタイムで確認できることです。 is スケーリング。これにより、(最も可能性が高い)過度に楽観的な予測を修正できます。
4:少数の人々が、収集されたデータに待ち行列理論を適用して、正確な予測を導き出します。
なぜ人々は一般的に彼らが持っているスケーリング能力を過大評価するのでしょうか? ほとんどの場合、使用可能な使用率がある限り、応答時間(キューイング)は同じであると想定していますが、実際には、次のように使用率に応じてサービス時間が増加します。
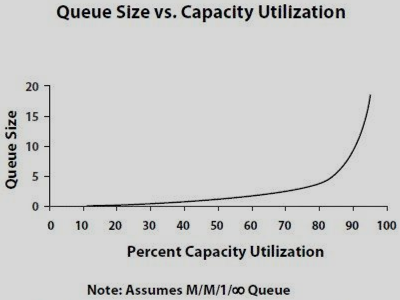
このパスをたどるストレージシステムのレイテンシーの実際の例を NetAppディスクのパフォーマンスと遅延の視覚化.
別の例:ディスクが使用率のパーセントごとに実行できるIO操作の数をプロットすると、ディスクがビジーになるにつれて、容量の別の%を使い果たす前に、IO操作が段階的に少なくなることがわかります。
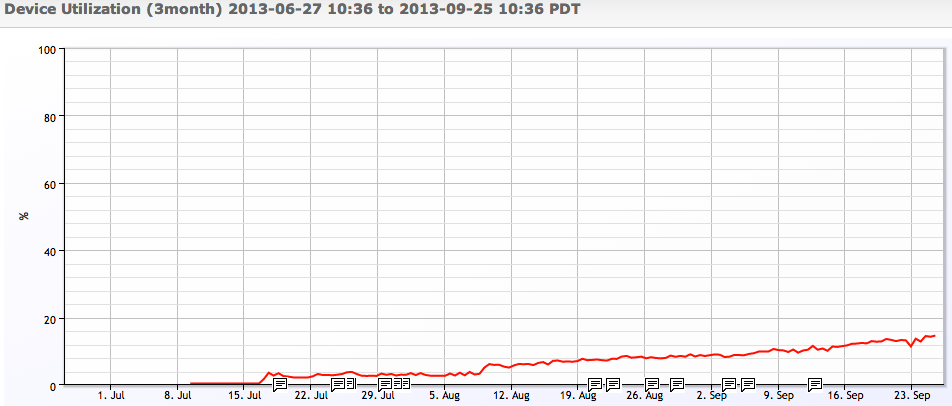
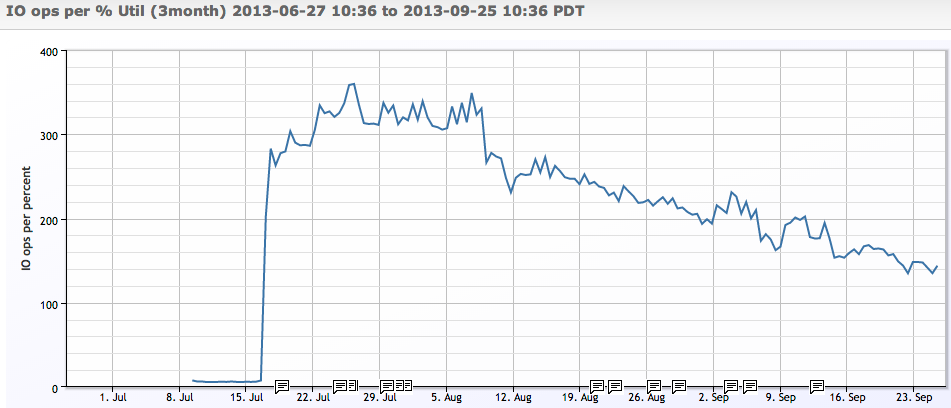
したがって、ここでのポイントは、インフラストラクチャの拡張性を把握したい場合は、あらゆる種類の決定を行うための監視とデータが必要であるということです。 非常に高価なリソースを扱っている場合を除いて、統計モデルをデータに適用する必要はおそらくありませんが、使用率によるパフォーマンスの線形性を想定するのは誤りであることに注意してください。 使用率を70%未満に保ち、実際にワークロードの応答を監視するために負荷とパフォーマンスの傾向を把握していることを確認してください。問題はないはずです。