
テクノロジーに大量のデータの収集が含まれる場合は、Elasticsearchを使用している可能性があります。 そうである場合は、Elasticsearchクラスターを監視する必要があります。 Elasticsearchで構成可能なほとんどすべてが、その広範なAPIを介して管理できます。 同様に、クラスターとノードの状態に関する豊富な情報、および低レベルのシャードとインデックスのメトリックをAPI呼び出しから取得できます。 LogicMonitorの簡単にカスタマイズ可能なデータソースを使用すると、この情報を監視するためのデータソースを簡単に作成できます。

全体的なクラスターの状態は、最初に確認して警告するもののXNUMXつです。 Elasticsearch RESTfulAPIエンドポイントを介して / _cluster / health、次のjson出力を取得できます。
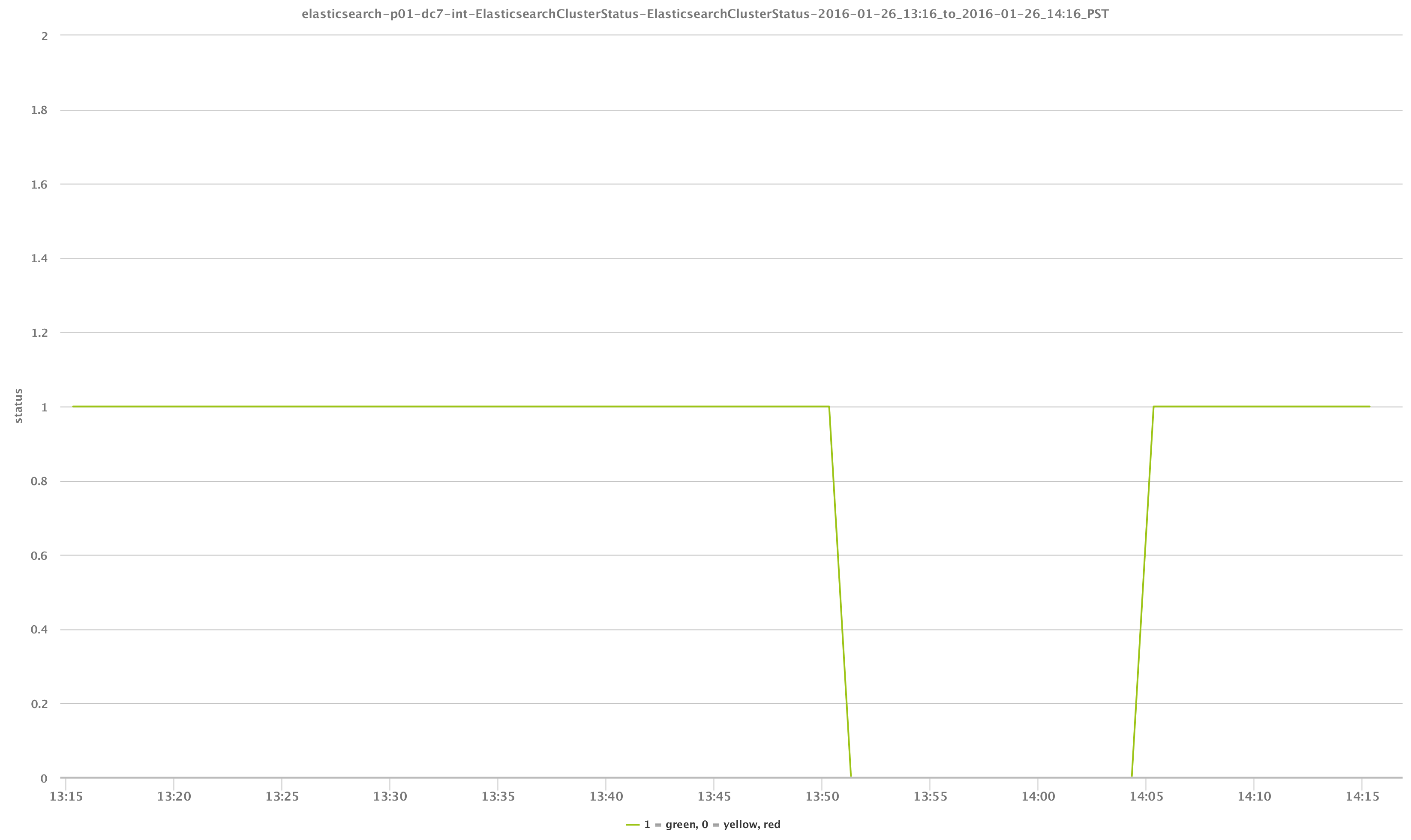
LogicMonitorデータソースで単純なGETリクエストを使用することで、「ステータス」を照合し、クラスターの状態を簡単に判断してアラートを出すことができます。 これは、以下のグラフに示されています。 この場合、クラスターノードのXNUMXつが失われたため、ステータスが一時的に緑色ではなかったことがわかります。
{kind=link}
非常に重要ですが、ステータスメトリックは、視覚化の観点からはあまり興味深いデータポイントではありません。 おそらくもう少し視覚的に興味深いですが、下のグラフから、全体的なCPU容量とクラスターの使用状況を次のように確認できます。 / _cluster / stats API呼び出しと、上のグラフに示されている停止がCPUの状態にどのように影響したか。
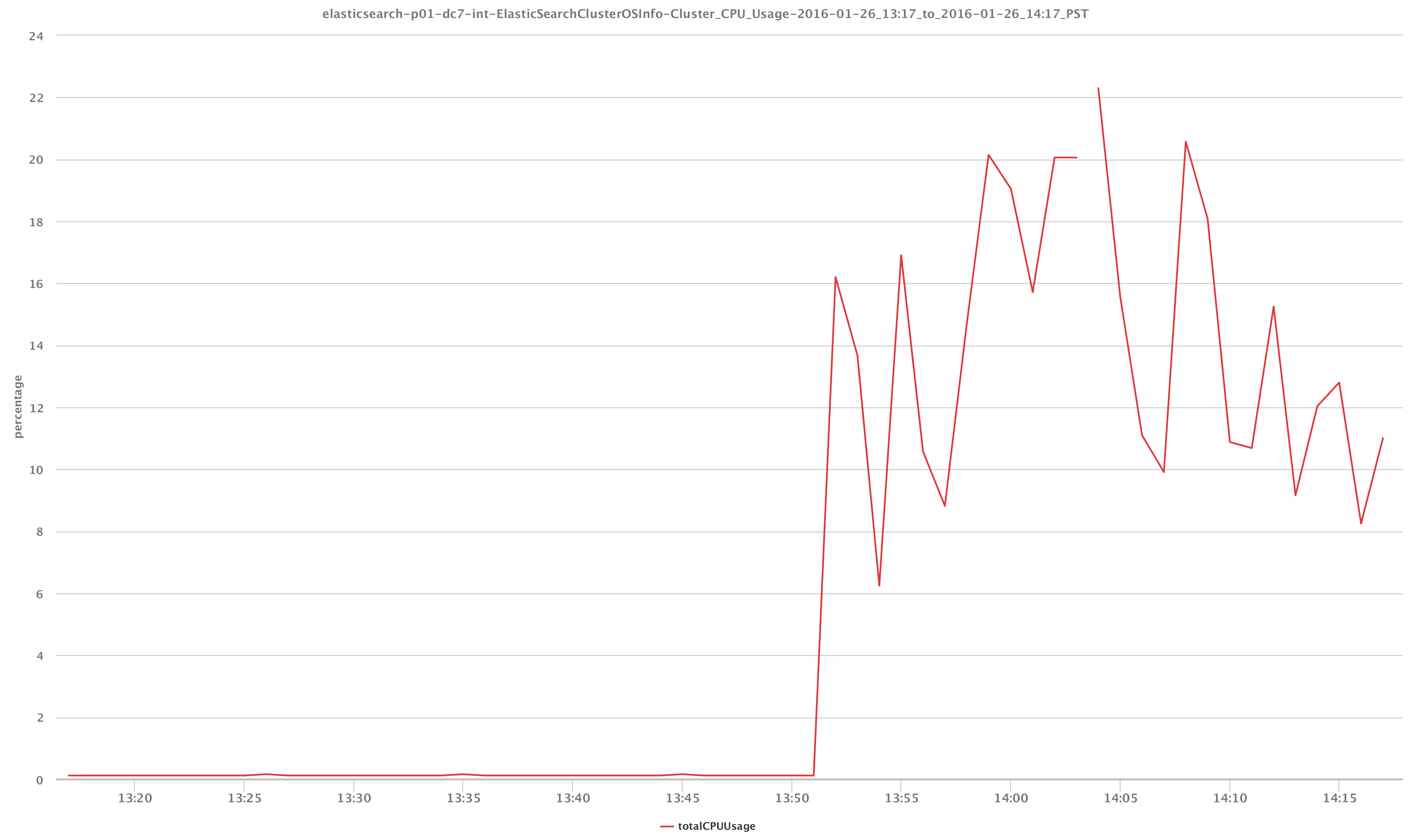
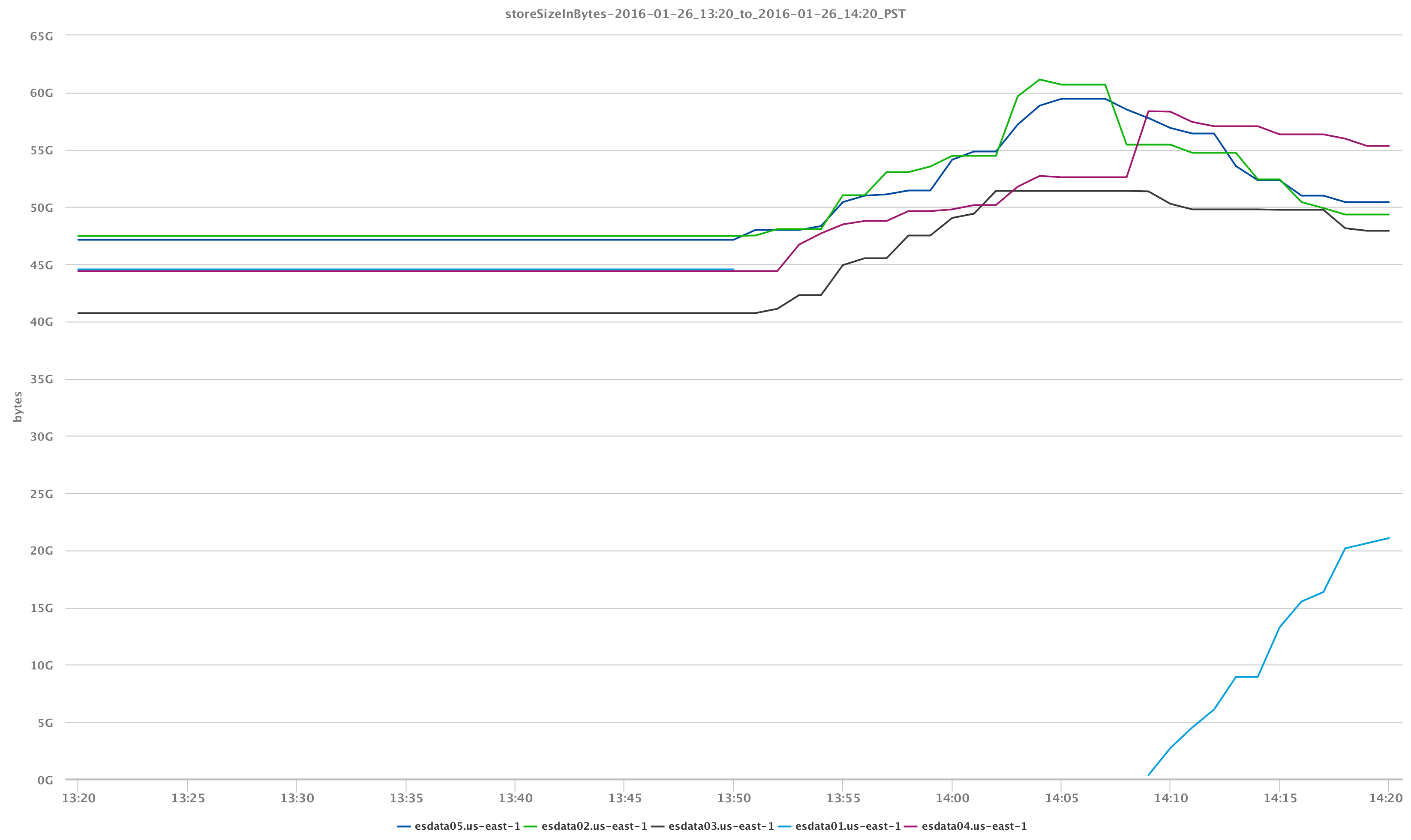
Elasticsearchについて少し知っていて、ノードを失ったという事実を考えると、CPU使用率の急上昇の原因は、クラスターが他のデータノードにシャードを再割り当てしてノードあたりのストレージに直接影響を与えているためであることがわかります。上手。
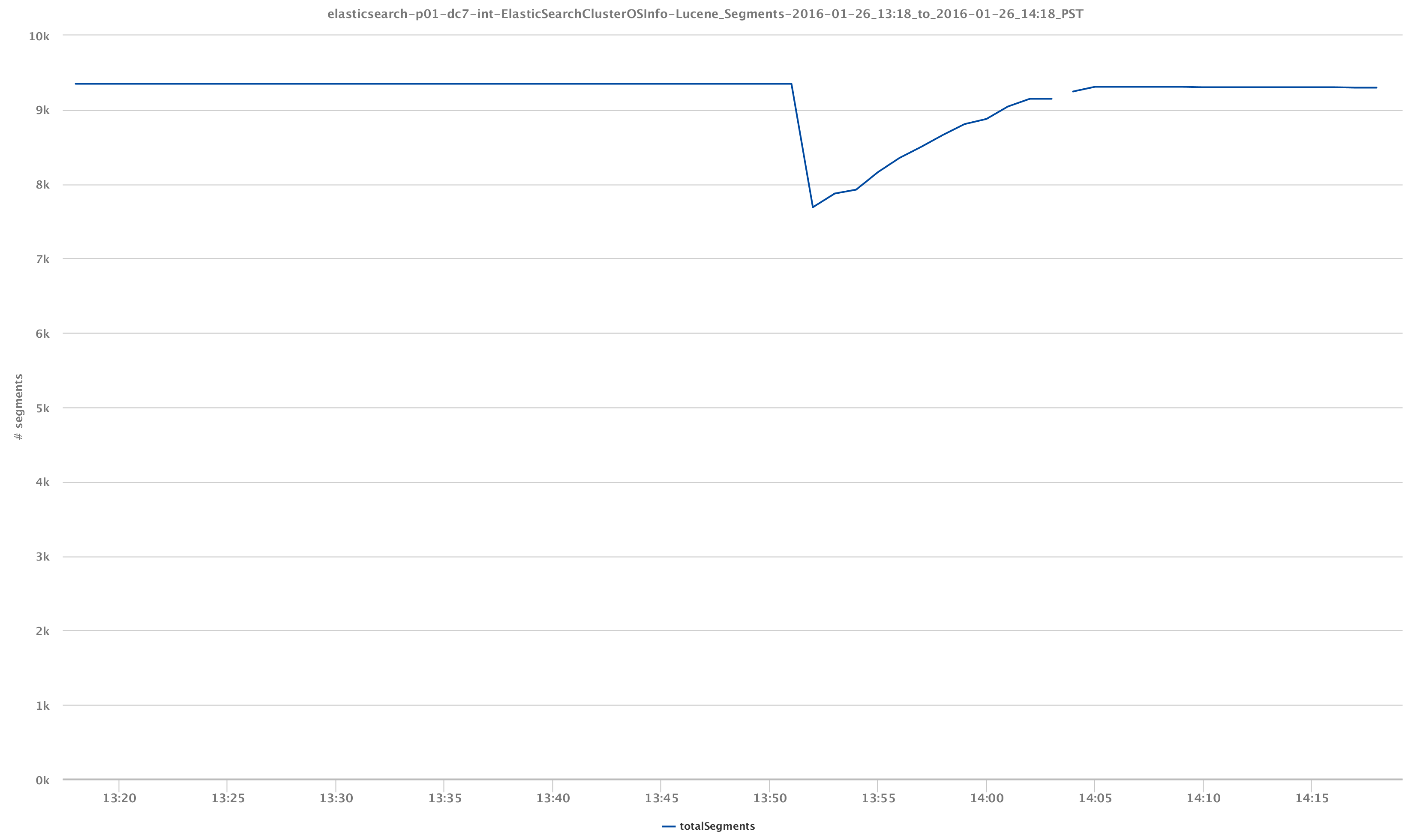
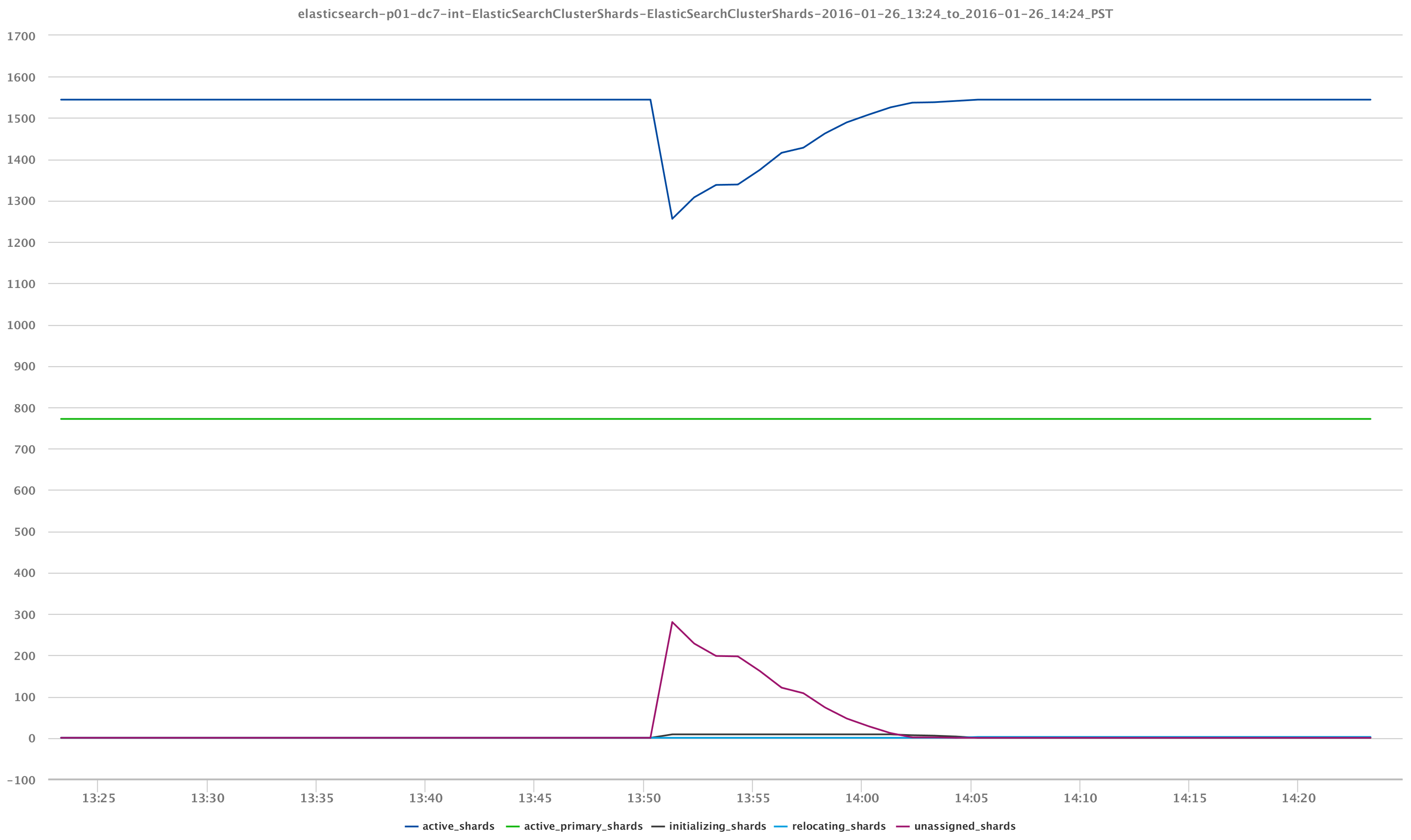
クラスターの状態を視覚化することは、達成できることのXNUMXつの側面にすぎません。 インデックスを作成している実際のデータを調べると、よりエキサイティングになります。 たとえば、再び / _cluster / stats & / _cluster / health API呼び出しでは、データノードが失われたイベントの影響を受けたLuceneセグメントとインデックスシャードの動作を観察できます。
確かに、elasticにはElasticsearch固有の監視ソリューションであるMarvelとWatcherがありますが、LogicMonitorの柔軟性により、XNUMXつのガラス板でインフラストラクチャ全体を監視することができます。
これは、Elasticsearchクラスターの監視の非常に高レベルの概要であり、LogicMonitor内の柔軟なデータソースフレームワークを介して簡単に実現する方法です。 Elasticsearchのモニタリングに関する次のブログ投稿では、新しいアマゾンウェブサービスElasticsearchサービスのモニタリングの詳細に飛び込み、新しいサービスと独自のクラスターのモニタリングの違いについて説明します。