
セキュリティパッチがクラウドユーザーに与える影響
最近公表されたものなど、ハードウェアに影響を与える重大なセキュリティ上の欠陥が特定された場合 チップの脆弱性 (Meltdown、Spectre)—クラウドプロバイダーは、インフラストラクチャを保護するために必要なパッチを実装するための手順を実行します。
クラウドプロバイダーによって実行される更新では、クラウドリソースのスケジュールされた再起動が必要になる場合があります。 たとえば、Intelプロセッサのセキュリティパッチにはハイパーバイザーカーネルの更新が含まれているため、マシンを再起動する必要があります。
クラウドリソースがサポートする内容に応じて、クラウドプロバイダーからの再起動では、アクションを実行する必要がある場合とない場合があります。 の再起動 アマゾンウェブサービス(AWS)EC2 本番アプリケーションを実行しているインスタンスは、開発の遊び場として使用されているインスタンスを再起動するよりも、ビジネス運用に大きな悪影響を与える可能性があります。
LogicMonitorがどのように役立つか
使い方 LMクラウド、そのようなスケジュールされたイベントの前にアマゾンウェブサービス(AWS)サービスアラートを受信し、監視対象のインフラストラクチャのコンテキストでそれらを表示します。
イベントごとに、関連付けられたEC2インスタンス、スケジュールされたイベントのタイプ(再起動、リタイアなど)、およびイベントの発生がスケジュールされるまでの時間が表示されます。 LogicMonitorのインスタンスに対してスケジュールされた再起動のいくつかを次に示します。
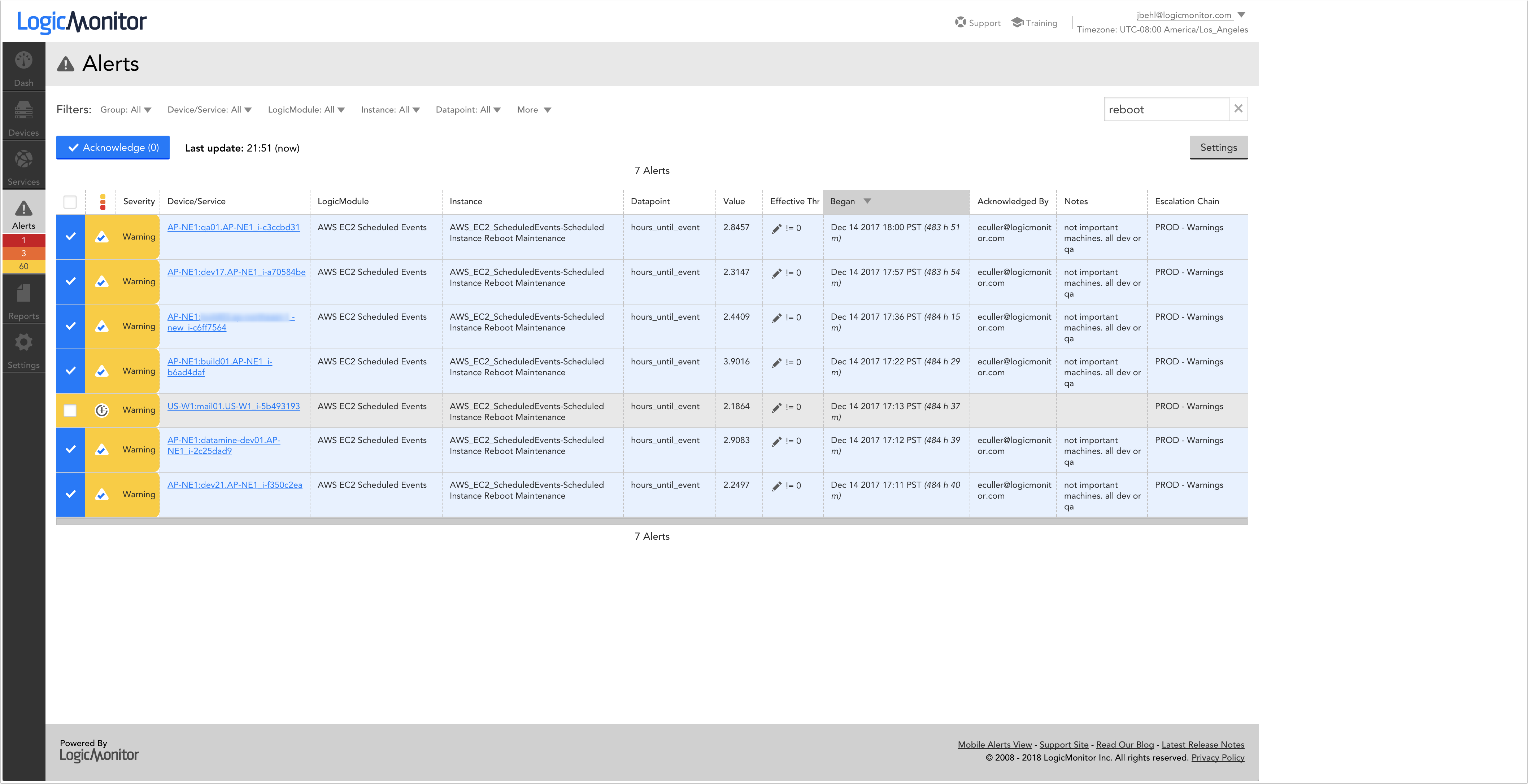
アラートのインテリジェントルーティング
AWSは電子メール(はい、電子メール)を使用して、今後予定されているイベントをユーザーに通知しますが、アラートツールとしての電子メールの有効性は、受信者と、受信者がその重要性と影響を受ける可能性のあるインスタンスを認識しているかどうかによって異なります。
LogicMonitor、アラートの送信先の決定は、体系的に定義できます。 アラートルーティングとメッセージングは、EC2インスタンスとイベントのタイプまたはステータスに依存する可能性があります。
たとえば、重要な本番インスタンスのスケジュールされた再起動のアラートをテキスト経由でオンコールエンジニアにルーティングし、ミッションクリティカルでない開発インスタンスのスケジュールされた再起動のアラートをSlackルームに送信するように選択できます。
未確認のアラート(つまり、応答されていないアラート)のレポートを構成して、運用チームの受信トレイの責任者に定期的に配信することもできます。
パフォーマンスの変化の測定
イベントが発生した後、LogicMonitorの監視データを使用して、結果として生じるパフォーマンスの変化を測定できます。 チップの欠陥に対するセキュリティパッチの実装に関連する再起動イベントの前後のEC2インスタンスの4つのCPUを次に示します(イベントはXNUMX月XNUMX日に発生しました)。
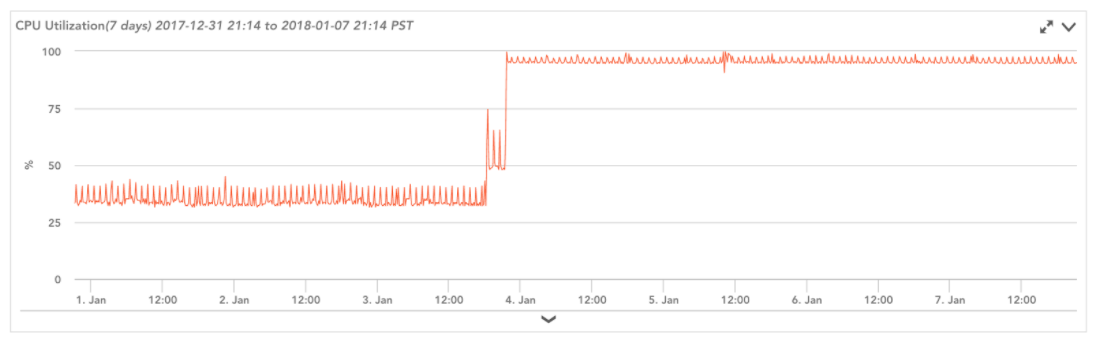
ご覧のとおり、このパッチによりCPU使用率が大幅に増加しました(この増加は私たちに固有のものではありませんでした)。 イベント (NOC ウォールなど) の後でインスタンスのパフォーマンスを積極的に監視していなくても、LogicMonitor のすぐに使えるアラートしきい値のおかげで、CPU 使用率のそのような増加に対してアラートが自動的にトリガーされます。

次のステップ
CPU使用率データに基づいて、拡張のためのヘッドルームを確保するためにインスタンスのサイズを変更する必要があることがわかります。 LogicMonitorのLMクラウドを使用して クラウドリソースを監視する つまり、スケジュールされたイベントの欠落を回避し、問題が発生する前にそれらが引き起こす可能性のあるパフォーマンスへの影響に対処することもできます。
LogicMonitorの LMクラウド ソリューションは、主要なリソースパフォーマンスメトリック、クラウドプロバイダーの可用性、およびクラウド環境の支出データを監視するため、自信を持ってクラウドをナビゲートできます。 LogicMonitorをまだ使用していない場合は、 無料試用 。

