
この投稿のタイトルは言葉で表現されていますが、その背後には意味と意図があります。 最近テキサス州オースティンで開催されたLogicMonitorのユーザー会議に参加した場合は、「レベルアップ」が共鳴します。 それが私たちのイベントの名前とテーマでした。 また、「可視性」、「柔軟性」、「速度」という用語を使用して、24のブレークアウトセッションをトラックに編成し、ユーザーが拡張方法を学習できるようにしました。 視認性 ITインフラストラクチャを超えてビジネスクリティカルなサービスやシステムに移行し、問題をより効率的に解決します (柔軟性)、そしてより速く革新する(速度)。 冒頭の基調講演では、LogicMonitorプラットフォームの強力な新開発を発表およびデモンストレーションしました。 これらの発表は、柔軟性、可視性、速度にも関係しています。 ここでそれらに入りましょう。
透明性
LogicMonitorを使用すると、ユーザーはビジネスシステムの状態をすばやく確認でき、食品を安全な温度に保ち、糸車がお気に入りのストリーミングショーを中断せず、旅行の予約が数秒で完了します。 可視性を高めるために私たちが実証し発表したいくつかの革新は次のとおりです。
トポロジー
トポロジマッピングは、ネットワークとデバイスの動的な視覚化を提供し、ユーザーがリソース間の依存関係を理解し、問題をより迅速にトラブルシューティングできるようにします。 また、LogicMonitorAIOps機能の基盤を築きます。 LogicMonitorのトポロジマッピングは、多数の検出プロトコルを使用して、監視対象のリソース間の関係を自動的に識別します。 たとえば、Link Layer Discovery Protocol(LLDP)とCiscoのCisco Discovery Protocol(CDP)を使用して、多くのリソース(スイッチ、ホスト、ファイアウォール、ルーター、その他のネットワークコンポーネントなど)間の依存関係とデータフローを示すネットワークトポロジマップを動的に生成します。 )ご使用の環境で。
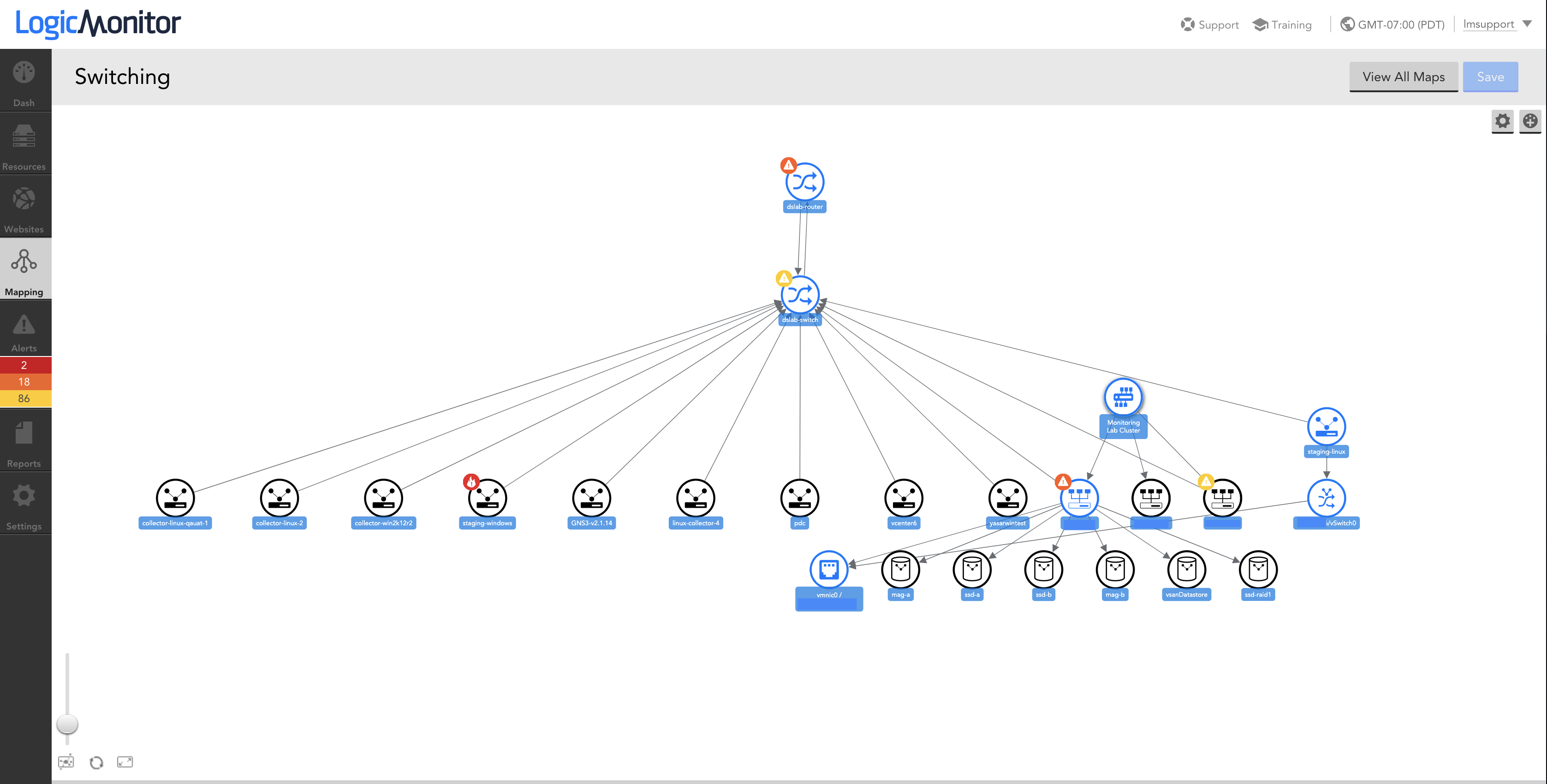
Kubernetesモニタリング
アプリケーションをコンテナ化すると、デプロイメントが高速化され、アプリケーションのスケーリングと移植性が容易になります。 しかし、コンテナは一時的なものであるため、 コンテナ環境でアプリケーションとマイクロサービスの状態とパフォーマンスを監視することは困難です コンテナリソースを効率的に管理します。 現在利用可能なLogicMonitorのKubernetesモニタリングはエージェントレスであるため、すべてのノードにエージェントをインストールする必要はありません。 アプリケーションは、LogicMonitorの監視テンプレートの広範なライブラリを使用したベストプラクティスに基づいて自動的に検出および監視されます。 Kubernetesノード、ポッド、コンテナ、サービス、マスターコンポーネントのデータが自動的に収集されます(例:.スケジューラー、api-server、controller-manager)。 クラスターリソースは、クラスターで実行されているアプリケーションによって監視に自動的に追加および監視から削除されるため、監視を最新の状態に保つことを心配する必要はありません。 事前設定されたアラートしきい値は、すぐに使用できる意味のあるアラートを提供します。 これは、構成ファイルを編集したり、一致するコンテナーイメージ名に依存したり、手動で監視を構成したりする手間をかけずに、コンテナー化されたアプリケーションを即座に可視化できることを意味します。 さらに、LogicMonitorは、この詳細なパフォーマンスデータを最大XNUMX年間保持します。 これらの利点を組み合わせることで、LogicMonitorは、代替ソリューションよりも簡単に(そして、より少ないツールとプロセスで)Kubernetesクラスターを監視できます。
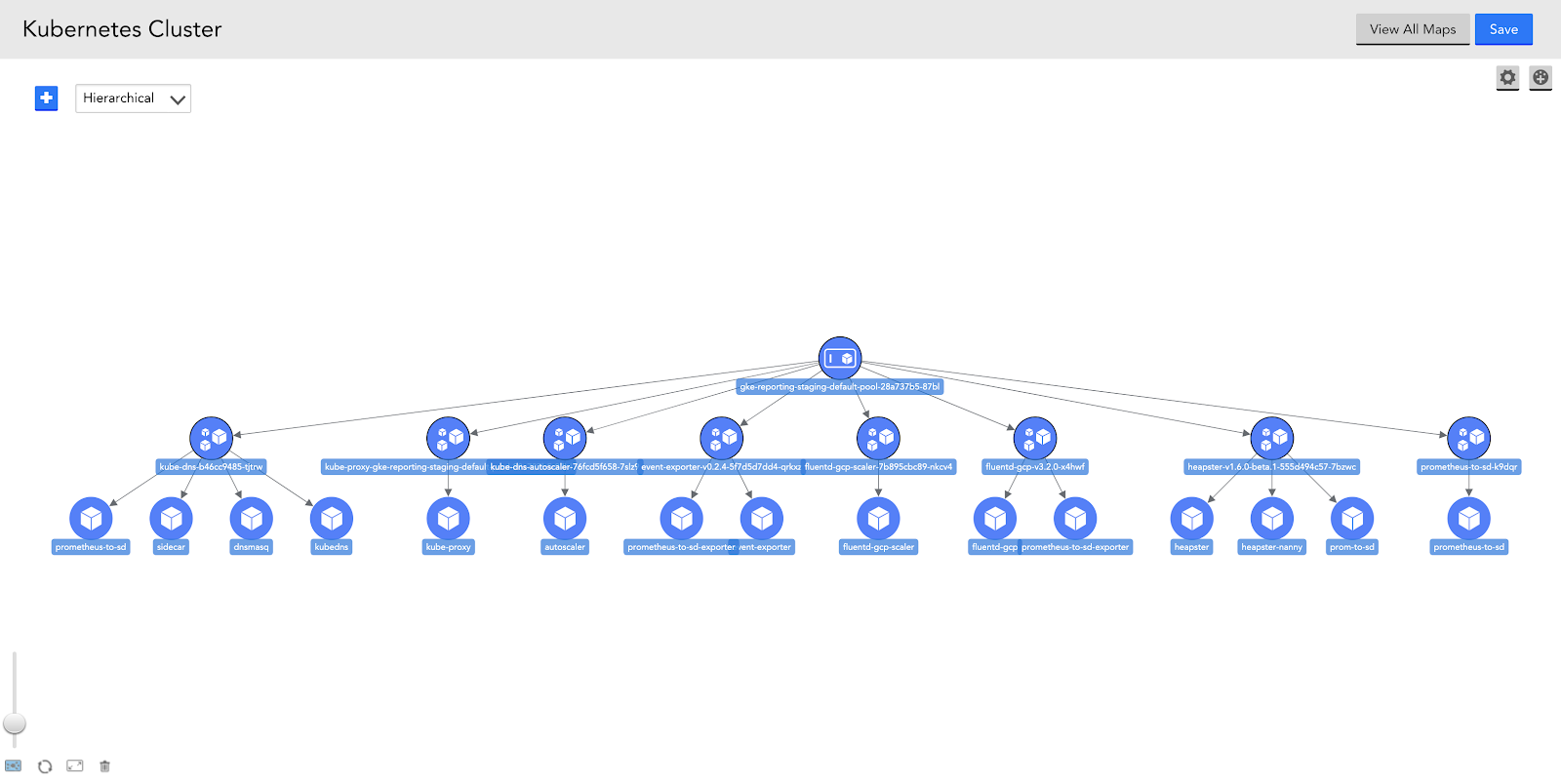
動的サービス監視
現在利用可能なLMService Insightを使用すると、ビジネスに不可欠なサービスとアプリケーションの状態に関する貴重な洞察を得ることができます。 LM Service Insightを使用すると、XNUMXつ以上の監視対象リソース(デバイス、クラウドリソース、コンテナなど)のインスタンスを論理的な「サービス」にグループ化し、これらのインスタンス全体のサービスレベルインジケーターを集約してサービスレベルのデータを取得し、監視することができます。そのサービスレベルのデータを視覚化して警告します。 動的なサービスの監視とアラートにより、アラートノイズを減らし、トラブルシューティングを迅速に行い、長期的なパフォーマンストレンドを特定し、ビジネスクリティカルなサービスの全体的な状態についてチームに情報を提供できます。 たとえば、LM Service Insightを使用して、多数のコンテナで実行されているアプリケーションを監視できます。この場合、個々の一時的なコンテナ化されたアプリケーションインスタンスは、必ずしもアプリケーション全体のパフォーマンスを示すとは限りません。
LogicMonitorの顧客であるQ2Holdingsは、LM Service Insightを使用して、HashiCorp Nomadクラスターのパフォーマンスを視覚化およびレポートし、追加の容量をより正確に予測します。 ノードクラスがメモリやその他のリソースを使いすぎていることを追跡し、ノードまたはデバイス自体がアラートを発行するのを待たずに、即座にアラートを受信できます。
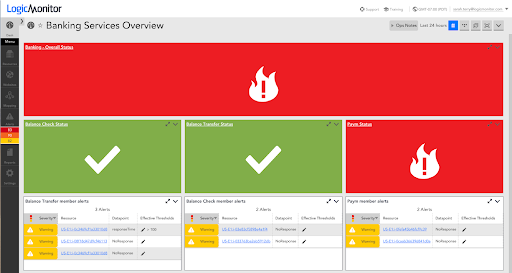
サポートしているアプリケーションとリソースのステータスを以下に示します。
UX / UIアップデート
よりシームレスで直感的で魅力的なユーザーインターフェイスをユーザーに提供するために、LogicMonitorの新しいUIは、ワークフローを合理化し、クリックを減らし、ITOPSチームの効率を高めるように設計された多数の新機能を含めるのに役立ちます。 高度な検索機能を含む新機能の展開に加えて、UIの更新により、ユーザーはより高速で応答性の高いインターフェイスを提供し、ユーザーのさまざまな問題点に対処できます。 更新されたインターフェースの最初のロールアウトは、わずか数か月で表示されるアラートページです。
柔軟性
モニタリングは、ITおよびDevOps情報を視覚化するだけでなく、ビジネスを成長させるための新しい方法を開く必要があると考えています。 ユーザーが問題が発生する前に回避できる場合、ユーザーはメンテナンスからイノベーションに焦点を移すことができます。 柔軟性は、固有の環境ごとに監視をカスタマイズする機能など、これを実現するのに役立ちます。 柔軟性の傘の下で、私たちは次のことを発表しました。
LMエクスチェンジ
お客様は、LogicMonitorモニタリングテンプレートを使用して特定のニーズに合わせてモニタリングをカスタマイズし、新しいデバイス、テクノロジー、およびリソースをサポートすることがよくあります。 LM Exchangeを使用すると、LogicMonitorユーザーは、顧客、パートナー、開発者、またはLogicMonitorによって作成されたかどうかに関係なく、すべてのLogicModule(DataSource、EventSources、PropertySourcesなど)を50つの集中リポジトリで検索および参照できます。 ユーザーは、コンテンツを検索または共有するためにコミュニティフォーラムに投稿したり、検索したりする必要はありません。 同じインターフェイスを使用して、公式モジュールを更新し、非公開で公開されたExchangeモジュールを管理できます。 コミュニティから公開されているすべてのモジュールは、利用可能になる前にLogicMonitorによるセキュリティとコンテンツのレビューを受けているため、コードが精査され、テストされていることを確認できます。 LM Exchangeの「安全なインポート」機能を使用すると、高度にカスタマイズされた公式のLMLogicModuleでも数回クリックするだけで更新できます。 ユーザーは、更新時に保持するカスタム変更を選択できます。 クローンを追跡したり、変更を手動でコピーしたりする必要はありません。 一括インポートオプションもあるので、XNUMX個のLogicModuleの更新を取得することを恐れている場合は、「AppliesTo」を微調整しました。恐れることはありません。 リストからそれらを選択し、AppliesToを保持することを選択するだけです。 ベータへの参加に興味がありますか? Eメール [メール保護] 参加する。
速度
LogicMonitorは、オンプレム、リモートデータセンター、およびパブリッククラウドで、サービスとインフラストラクチャの状態を包括的に監視するために展開できる、真に統合された監視プラットフォームです。 in 分。 「速度」という用語を使用するときは、LogicMonitor機能が検出までの時間(MTTD)と解決(MTTR)を短縮する多くの方法を指します。 今日の複雑なインフラストラクチャでは、サービスレベルアグリーメント(SLA)に必要な時間枠内で問題を優先順位付け、トラブルシューティング、および分析することが常に実行可能であるとは限りません。 収集された膨大な量のデータにより、これらの問題を視覚的に処理することは不可能です。 私たちの目標は、お客様が発生する前に何が起こっているのかを確認し、リスクを理解し、ニーズを予測できるようにすることです。 LMによって、ユーザーが運用効率とイノベーションを加速できるようになる方法は次のとおりです。
LMインテリジェンス
ロジックモニターのAIOpsソリューションであるLMインテリジェンスは、相関関係と信号についてシステムデータを継続的に監視して、関係とパターンを抽出し、将来の結果を予測し、深刻な問題を防ぐための早期警告システムとして機能します。 プラットフォーム全体の監視データを継続的に分析し、そこから学習してより深い洞察を提供します。 これは、リアクティブモードから移行してインフラストラクチャをプロアクティブに管理し、ノイズをカットして問題をより効率的に特定するのに役立ちます。 混乱に迅速に対処して防止するために必要なすべてのデータを提供します。 レベルアップでは、LMインテリジェンスの次の機能を発表しました。
異常の検出と視覚化 予想または通常のパターンに準拠していないデータを識別できます。 高度な機械学習アルゴリズムを採用することにより、LogicMonitorはデータポイントの予想されるデータパターンを確立し、これらのパターンの範囲外のデータを簡単に識別できるようにします。 これにより、リソースの動作に関する視覚的な表現と洞察の別の手段が提供され、ユーザーは、より深刻なイベントにエスカレートする前に問題をキャッチできる可能性があります。
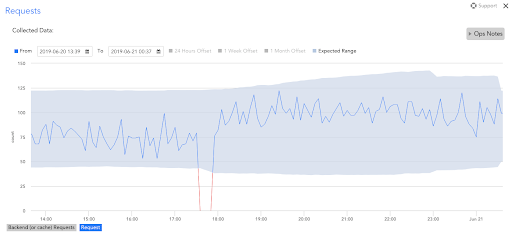
異常 で利用可能な視覚化 LogicMonitorv121。
3年第4四半期/第2019四半期に利用可能な異常アラート。
LogicMonitorカスタマーサクセスマネージャーに連絡して、ベータ版に参加してください。
アラートの依存関係: キーデバイス(ファイアウォールなど)に障害が発生すると、他の依存デバイスや完全な環境に悪影響を与える可能性があります。 これが発生すると、アラートストームが発生します(ファイアウォールの問題に対してアラートがトリガーされ、ファイアウォールに関連付けられているすべてのデバイスに対してアラートがトリガーされます)。 これは、問題の根本原因を特定するために数十または数百のアラートをふるいにかける必要があるため、ITOpsにとって深刻な問題です。 アラートの依存関係はこの問題を解決します。 トポロジマッピングによって自動的に検出された関係を使用して、アラートの依存関係はメタデータをアラートに追加し、依存するアラートの通知を防ぎます。 インシデントのルートアラートまたは発生原因アラートと見なされるアラートのみをルーティングします。 例:ダウンしたコアスイッチの背後にあるためにアラートを出している依存デバイスのアラートは、依存アラートとしてマークされます。 追加の依存関係データにより、ユーザーはLogicMonitorで依存アラートを表示し、それらのアラートのルーティング通知を無効にするかどうかを決定できます。 これにより、アラートのノイズを減らし、アラートの依存関係のインシデントが発生したときにアラートの嵐を防ぐことができます。 第4四半期に利用可能になりました。ベータ版に参加するには、カスタマーサクセスマネージャーにお問い合わせください。
それを包み込む
レベルアップブレイクアウトセッション全体での平均コンテンツレーティングは4.53(1〜5のスケールで5が優れています)、平均スピーカーレーティングは4.68であり、調査結果とユーザーフィードバックにより、私たちは正しい方向に進んでいることがわかります。 これらの機能や今後の機能により、ユーザーが視力を視覚に変える手助けをすることに重点を置いています。 LogicMonitorをまだ使用していない場合は、 ここで無料トライアル.

