
誰もが知っている理由から、AWSは素晴らしいです。 インスタンスとサービスを必要なときにすぐに起動できるため、組織の俊敏性と応答性が向上します。 ただし、多くの人や部門がサービスをプロビジョニングできるため、サービスを見失い、必要になった後もリソースを実行したままにしておくのは簡単です。 これは環境の複雑さを増すだけでなく、お金を浪費します。
LogicMonitorのAWSモニタリングは、未使用または過剰にプロビジョニングされたリソースを特定することで、AWSコストの管理に役立ちます。 また、LogicMonitorは、すべてのリージョンにわたって、さらには複数のAWSアカウントにわたってこれらのシステムを表示できるため(たとえば、本番AWSアカウントと開発AWSアカウントの両方のビューが分離されている場合はそれらを組み合わせる)、最も無駄なリソースを最初に簡単に特定できます。彼らがどこにいても。 私たちはここLogicMonitorでこのプラクティスを経験し、私たちが行ったこととそれをどのように行ったかを共有する価値があると考えました。 LogicMonitorで、さまざまなリージョンで未使用のEC2インスタンスがいくつか見つかりました。 未使用のDynamoDBテーブルの削除に失敗したコードのソフトウェアバグ、およびテーブルにお金を残していた他のいくつかのケース。 (むしろ、Amazonにそれを与える。)
まず、「AWSの十分に活用されていないリソース」と呼ばれる新しいダッシュボードを作成しました。 (もちろん、以下のすべての前提条件は、LogicMonitorのAWSモニタリングを使用して、すべてのAWSリソースの詳細なメトリックを取得していることです。)
次に、さまざまな高度なカスタムグラフウィジェットを追加し、さまざまなタイプの最も使用率の低いリソースを表示しました。 いくつかの例を見ていきます。
EC2インスタンス
EC2インスタンスの場合、AWSは停止したインスタンスに対して課金しないため、ビューから除外する必要があります。 これを行う最も簡単な方法は、停止していないすべてのインスタンスを含む動的デバイスグループを作成することです。 新しいグループを作成し、デバイスを自動割り当てするように設定し、クエリをに設定するだけです。 hasCategory( "AWS / EC2")&& system.aws.stateName!= "stopped"


これにより、停止していないすべてのEC2インスタンスが2つのグループに収集され、カスタムグラフのソースとして使用できます。 これを行うには、AWSリソースダッシュボードに移動し、[高度なカスタムグラフウィジェットの追加]を選択して、タイトル(「アイドルEC1リソース」)を付けます。 デフォルトの時間範囲を2か月に設定します。 Y軸を「%アイドル」にします。 データポイントを追加します。 最初のデータポイントとして、上記で作成した動的グループをグループソースとして選択します。 デバイスを「*」に設定して、そのグループのすべてのメンバーを選択します。 AWS_EC10へのデバイスデータソース。 「*」へのインスタンス。 データポイントをCPUUtilizationに移動し、[結果を上位XNUMXに制限]を選択します。
次に、別のデータポイントを追加しますが、今回は[仮想データポイント]を選択し、IdlePercentという名前を付けます。 次のように、式を100-CPUUtilizationに設定します。
次に、表示するグラフの線にIdlePercentデータポイントを追加する必要があります。 これにより、上位10個のインスタンスがアイドル状態でソートされて表示されます。 これらすべてのデバイスで同じデータソースのみを参照している場合、デフォルトの凡例を## HOSTNAME ##のみに変更できます。
このウィジェットを保存すると、次のようなグラフが表示されます。
一般的にあまり使用されていないマシンがたくさんあります(これは、より小さく、より安価なインスタンスタイプに移行するための良いターゲットになる可能性があります)。 しかし、あなたはそのマシンを見ることができます docker.AP-NE1 先月はゼロロードで実行されていました。TechOpsチームによる簡単な調査により、Dockerコンテナをパイロットしたが、パイロットが本番環境に移行した後、この特定のマシンは使用されなくなったことが判明しました。マシンは決して終了しませんでした。
DynamoDB
Amazonは、DynamoDBテーブルのプロビジョニングされた容量が利用されているか、必要であるかに関係なく、その容量に対して課金します。 したがって、実際に使用している容量のどれだけを支払っているかを示す、別の高度なカスタムグラフウィジェットを用意することをお勧めします。
ここで役立つXNUMXつのビューがあります。 未使用の読み取り(または書き込み)プロビジョニングされた容量のパーセンテージを示すXNUMXつのグラフと、過剰にプロビジョニングされた読み取り(または書き込み)容量ユニットの数を示す別のグラフが必要です。
最初のビューには、まったく使用されていないテーブルが表示され、以下のようなカスタムグラフウィジェットを使用して簡単に作成できます(CapacityUsagePercentをトップ10ビューに設定してください)。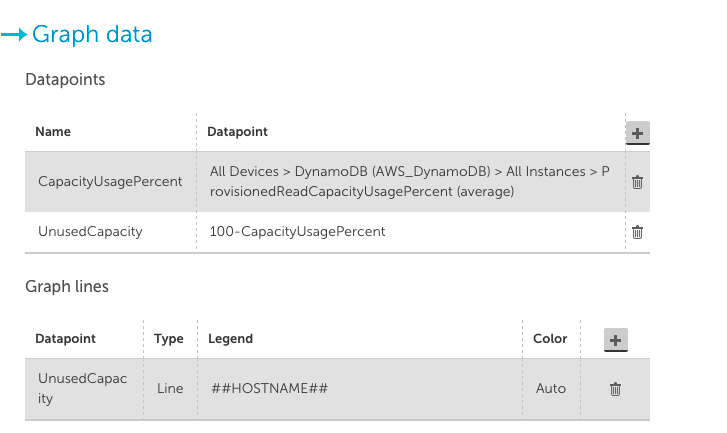
内部システムの場合、上記のグラフ構成は10個のdynamoDBテーブルを示しており、すべて100%未使用のプロビジョニングされた読み取り容量があります。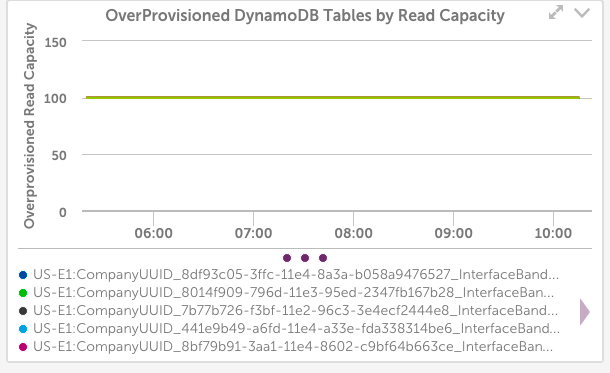
LogicMonitorは動的DynamoDBテーブルを使用してNetflowデータを保存します。DynamoDBテーブルを削除するはずのコードにバグがあったため、常にクリーンアップされていなかったことが判明しました。 監視がなければお金を無駄にし続けていたであろう別のケース。
DynamoDBでプロビジョニングされた容量のもうXNUMXつの便利なビューは、パーセンテージではなく容量単位の観点から表示することです。
以下のような構成は、無駄な容量単位ごとに上位10個のテーブルを示しています(ここでも、CapacityUsagePercentデータポイントを上位10個のビューに設定していることを確認してください)。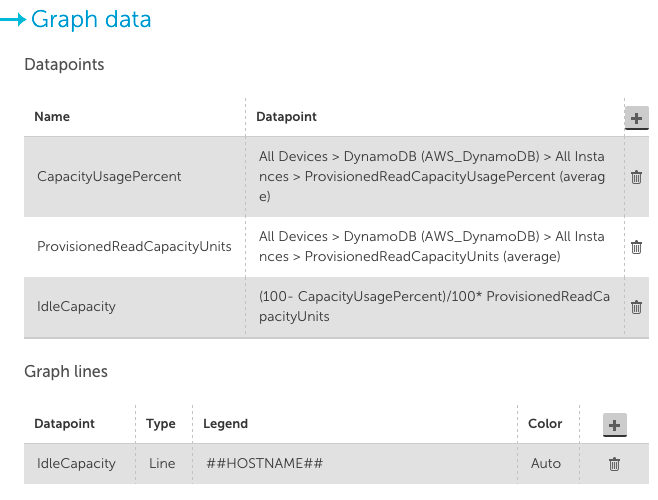
これにより、未使用の容量がテーブルのパーセンテージとして取得され、プロビジョニングされたユニットで重み付けされて、ユニットの観点からアイドル容量が得られます。 また、最もコストがかかるテーブルのプロビジョニングを調査できます。
私たちの場合、この見方はそれほど有益ではありませんでした: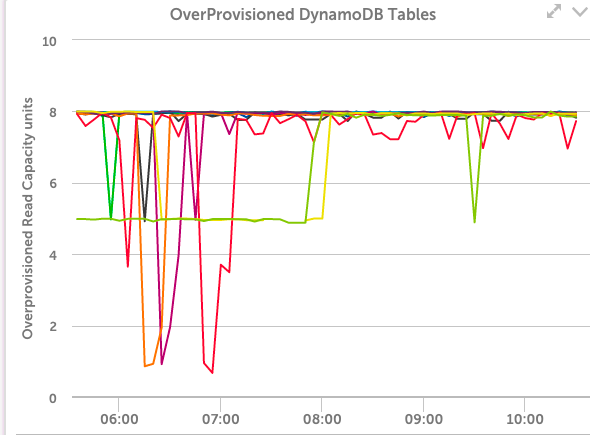
未使用容量のレベルが最も高いこれらのテーブルの中でも、すべてのテーブルが短期間でその容量をかなりのレベルまで使用していたことが示されました。したがって、使用する動的容量調整は正しく機能しているようです。
これらのタイプのカスタムグラフを他のAWSリソースタイプに対して繰り返すのは簡単です。 また、LogicMonitorでアカウントのC0stByServiceグラフを確認することで、ターゲットとするサービスを特定して、お金の行き先をすばやく確認できます。 (LogicMonitorでは、この手法で使用されていない、不要になったEBSボリュームも多数見つかりました。)
AWSに関する他のコスト削減のヒントがあればお知らせください。