LogicMonitorでは、主に大量の時系列データを扱います。 私たちの バックエンドインフラストラクチャプロセス 毎日数十億のメトリック、イベント、および構成。
以前のブログでは、からの移行について説明しました モノリスからマイクロサービスへ。 また、なぜ私たちが選んだのかを説明しました クォークス Javaベースのマイクロサービス用のマイクロサービスフレームワークとして。
このブログでは、以下について説明します。
- LogicMonitorマイクロサービステクノロジースタック
- マルチテナント環境でのKafkaパーティションレイアウトの使用方法
- KafkaでQuarkusをどのように使用したか
- マイクロサービスコンテナのスケールインおよびスケールアウトの方法
- 上位5つのKPI
LogicMonitorマイクロサービステクノロジースタック
環境内でQuarkusを使用して複数のマイクロサービスを構築したLogicMonitorのメトリックパイプラインは、次のテクノロジースタックにデプロイされています。
- Java 11(corretto、cuzライセンス)
- Kafka(AWS MSKで管理)
- Kubernetes
- Nginx(Kubernetes内の入力コントローラー)
マルチテナント環境でのKafkaパーティションレイアウトの使用方法
当社のマイクロサービスは、Kafkaトピックを使用して通信します。 各マイクロサービスは、いくつかのKafkaトピックからデータメッセージを取得し、処理結果を他のトピックに公開します。
Kafkaの各トピックはパーティションに分割されています。 同じKafkaクラスターを共有している複数のテナントのデータメッセージは、同じトピックに送信されます。
マイクロサービスがデータメッセージをKafkaトピックのパーティションに公開する場合、パーティションはランダムに、またはメッセージのキーに基づくパーティショニングアルゴリズムに基づいて決定できます。 同じデバイスからの時系列データメッセージが同じパーティションに順番に到着し、その順序で処理されるように、メッセージキーとして内部IDを使用することを選択しました。
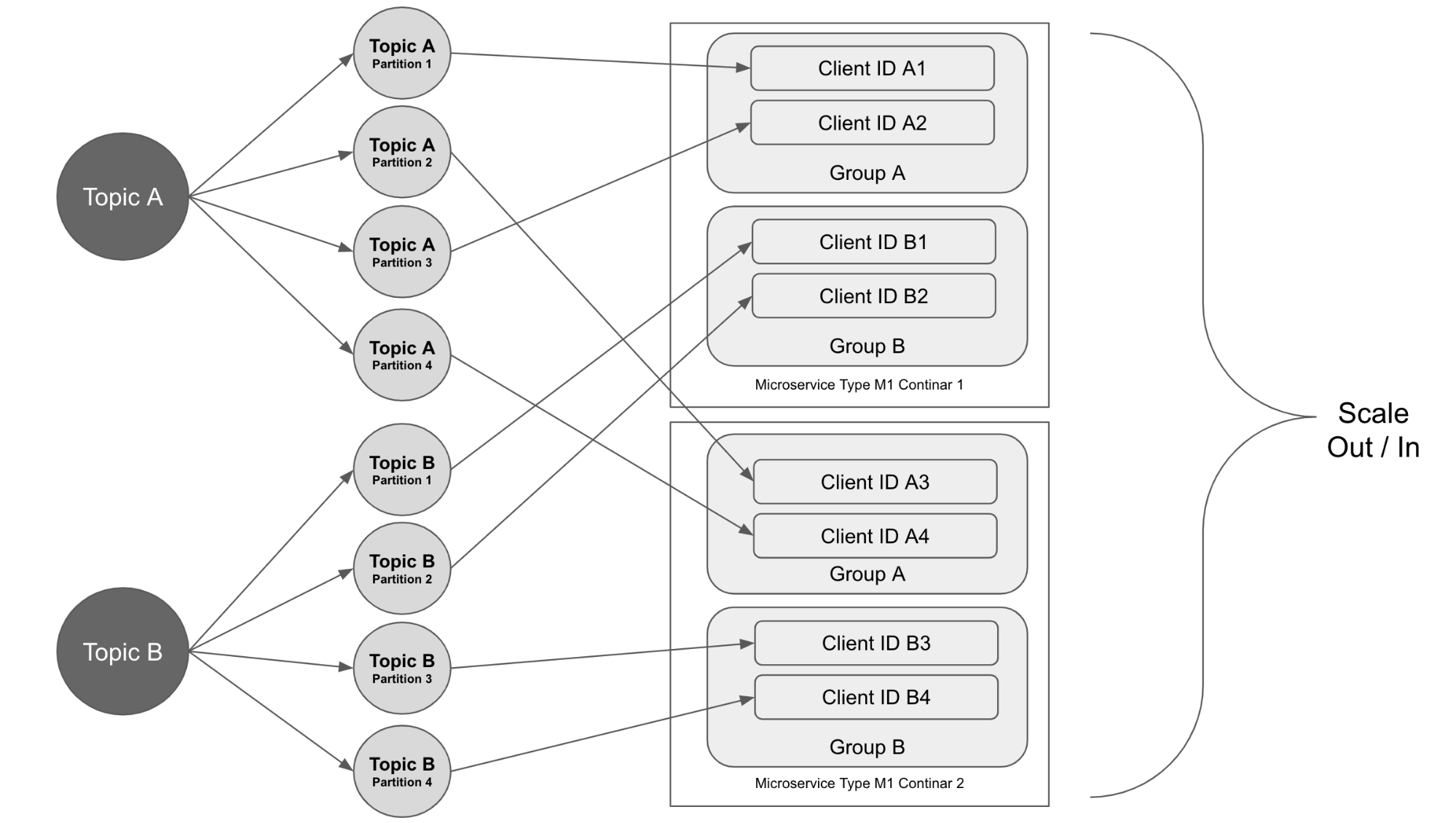
複数のパーティションにわたるトピックのデータは、バランスが崩れる場合があります。 この場合、一部のデータメッセージは他のパーティションよりも多くの処理時間を必要とし、一部のパーティションには他のパーティションよりも多くのメッセージがあります。 これにより、一部のマイクロサービスインスタンスが遅れます。 この問題を解決するために、データメッセージを複雑さに基づいてさまざまなトピックに分け、コンシューマーグループをさまざまに構成しました。 これにより、サービスをより効率的にスケールインおよびスケールアウトできます。
トピックのデータを消費するマイクロサービスでは、複数のインスタンスが実行されており、それらは同じコンシューマーグループに参加しています。 パーティションはグループ内のコンシューマーに割り当てられ、サービスがスケールアウトすると、さらに多くのインスタンスが作成され、コンシューマーグループに参加します。 パーティションの割り当てはコンシューマー間で再調整され、各インスタンスはXNUMXつ以上のパーティションを取得して作業します。
この場合、パーティションの総数によって、マイクロサービスがスケールアップできるインスタンスの最大数が決まります。 トピックのパーティションを構成するときは、大量のデータを処理するために必要なマイクロサービスのインスタンスの数を考慮する必要があります。
KafkaでQuarkusをどのように使用したか
MicroProfile ReactiveMessagingに基づくQuarkusのKafka拡張機能から始めました。 smallrye-reactive-messaging-kafka。 使いやすく、優れたサポートがあります 健康診断.
Kafkaプロデューサーを 命令型の使用法。 プロデューサーのスループットが良好であることを確認するために調整する必要のある構成がいくつかあります。これについては、 クォーカス vs スプリング ブログ。
- オーバーフロー戦略:デフォルトでは、プロデューサーのオーバーフロー戦略は小さなメモリバッファーの戦略です。 Kafka Emitterは、Kafkaコンシューマーからのシグナル(リアクティブメッセージング)を待って、特定のメッセージが正しく処理されることを認識します。 ただし、Kafkaコンシューマーが別のアプリケーションを使用していて、エミッターに信号を送信できない場合、これは悪いニュースです。 したがって、この戦略をNONEに設定します。 ここでのリスクは、Kafkaコンシューマーが追いついているかどうかを知るために、アプリケーション内に何も持っていないことです。 これは、KafkaクライアントのJMXメトリックを監視ソリューションで直接使用することで解決しました。
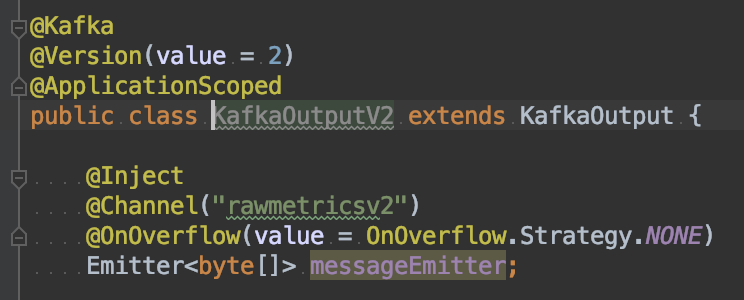
- WaitForWriteCompletion(構成セクションを参照) ここ):デフォルトでは、プロデューサーはメッセージが正しく完全に受け入れられたというKafkaからの確認応答を待っていました acksが0に設定されていても。 デフォルトでは、この構成値はtrueであるため、処理するデータの量に対応するために、falseに設定する必要がありました。
ただし、Kafkaコンシューマーを設定する際に、いくつかの課題がありました。 これらは、Quarkus vs.Springブログでも言及されています。
- 自動コミット:デフォルトでは、Quarkusコンシューマーは、すべてのメッセージが受信された後にKafkaにコミットしていたため、コンシューマーラグが大幅に増加していました。
- シングルスレッドの消費者:これにより、実際に メトリック処理にQuarkusKafkaコンシューマーを使用しないでください。 多くのトラブルシューティング時間と頭痛の種の後、私たちのチームは、それがシングルスレッドであるだけでなく、メッセージをシリアルに処理していることを発見しました。 ボリュームに追いつかなかったため、Apache Kafka Java SDKに基づいてKafkaコンシューマーを直接構築し、アプリケーションコンテナーごとに複数のコンシューマースレッドを作成できるようにしました。 ただし、Quarkus Kafkaコンシューマーは、構成が簡単であるという理由だけで、メッセージの量がはるかに少ない別のユースケースのために保持しました。

- QuarkusKafkaコンシューマーに関するその他の「落とし穴」は次のとおりです。
- あなたは非常に注意して返す必要があります 完了した将来、 そうしないと、リアクティブフレームワークが各メッセージを処理するのに時間がかかりすぎ、場合によっては無期限にハングすることがわかりました。
- @Incomingメソッドでスローされた例外も適切に処理されないため(コンシューマーは停止します)、ここでも注意してください。
- リアクティブメッセージングフレームワークのチャネル実装では、パターンに基づいてトピックを消費することはできません(つまり、チャネルごとにXNUMXつのトピックしか消費できません)。
最終的に、ApacheKafkaクライアントを使用してKafkaコンシューマーを実装することを選択しました。 たとえば、MicroProfile ReactiveMessagingのKafkaサポートに複数の改善が追加されました。 複数の消費者クライアントを許可する & パターンによるトピックのサブスクライブのサポート。 将来的には、QuarkusのKafka拡張機能をコンシューマー実装用に再評価する可能性があります。
マイクロサービスコンテナのスケールインおよびスケールアウトの方法
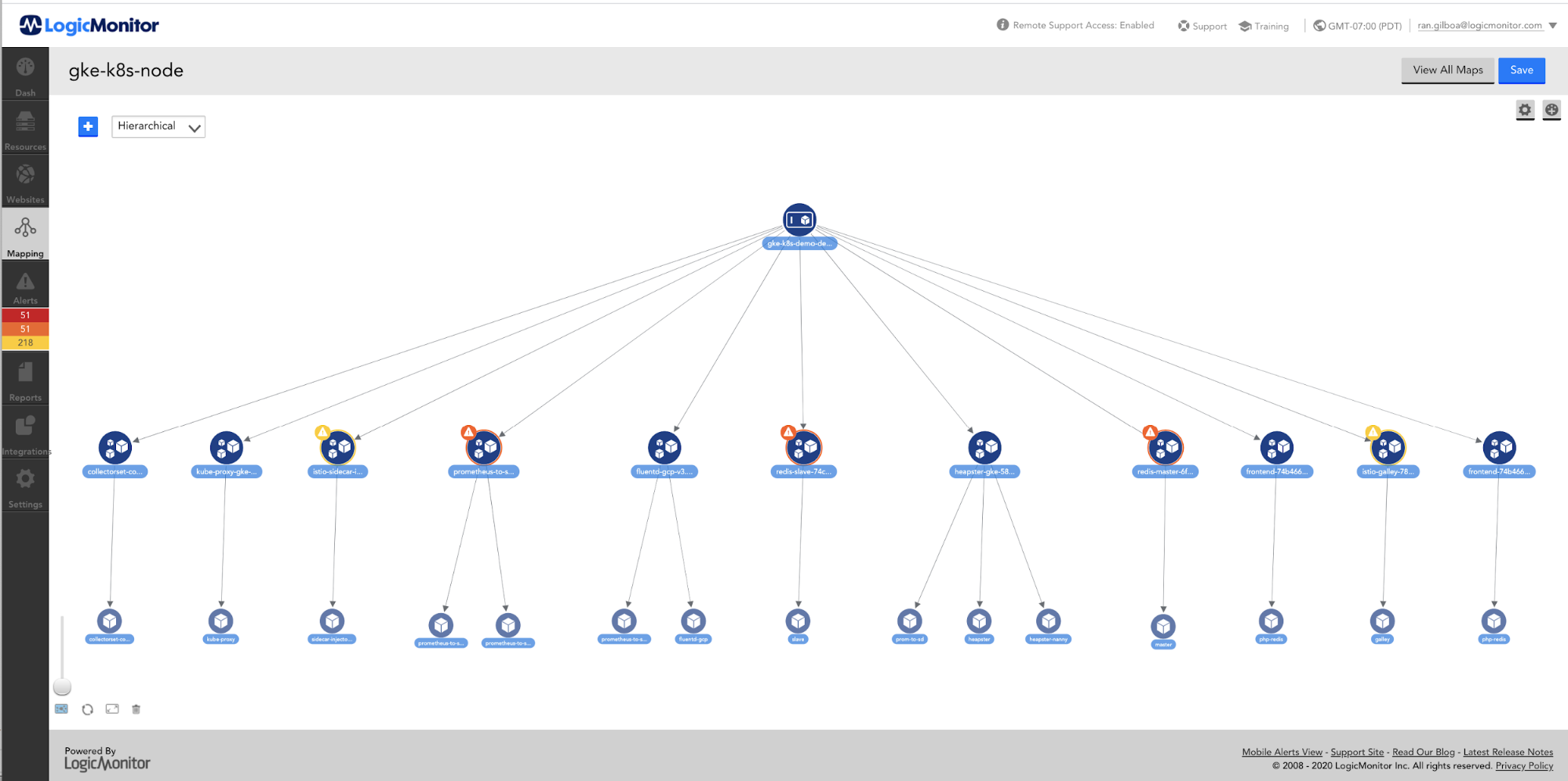
すべてのマイクロサービスは、KubernetesクラスターのDockerコンテナーにデプロイされます。 Kubernetesクラスターでは、複数の名前空間を使用して、複数のテナント間でリソースを分割します。 ほとんどのマイクロサービスは、名前空間レベルでデプロイされます。
クラスターレベルでは、Kubernetesクラスターはクラスターオートスケーラーによってスケールアップおよびスケールダウンできます。 名前空間内のマイクロサービスごとに、 水平ポッドオートスケーラー アプリケーションのCPU使用率に基づいて、コンテナーレプリカの数を自動的にスケーリングします。 名前空間内のマイクロサービスのレプリケーションの数は、その名前空間に属するテナントからの負荷によって異なります。 負荷が高くなり、マイクロサービスのCPU使用率が高くなると、サービスのレプリカが自動的に作成されます。 負荷が低下してCPU使用率が低下すると、それに応じてレプリカの数が減少します。 次の目標は、アプリケーションのカスタムメトリックで水平ポッドオートスケーラーを使用することです。
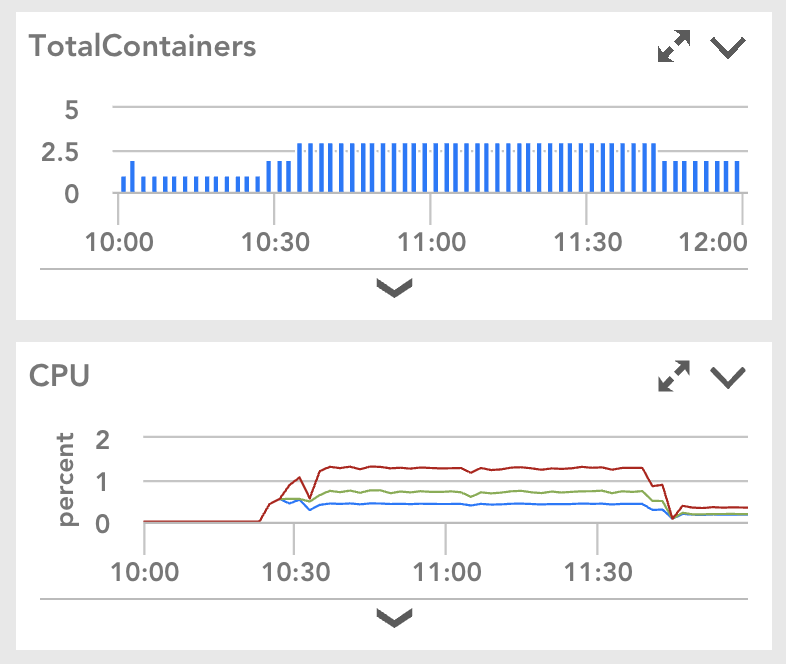
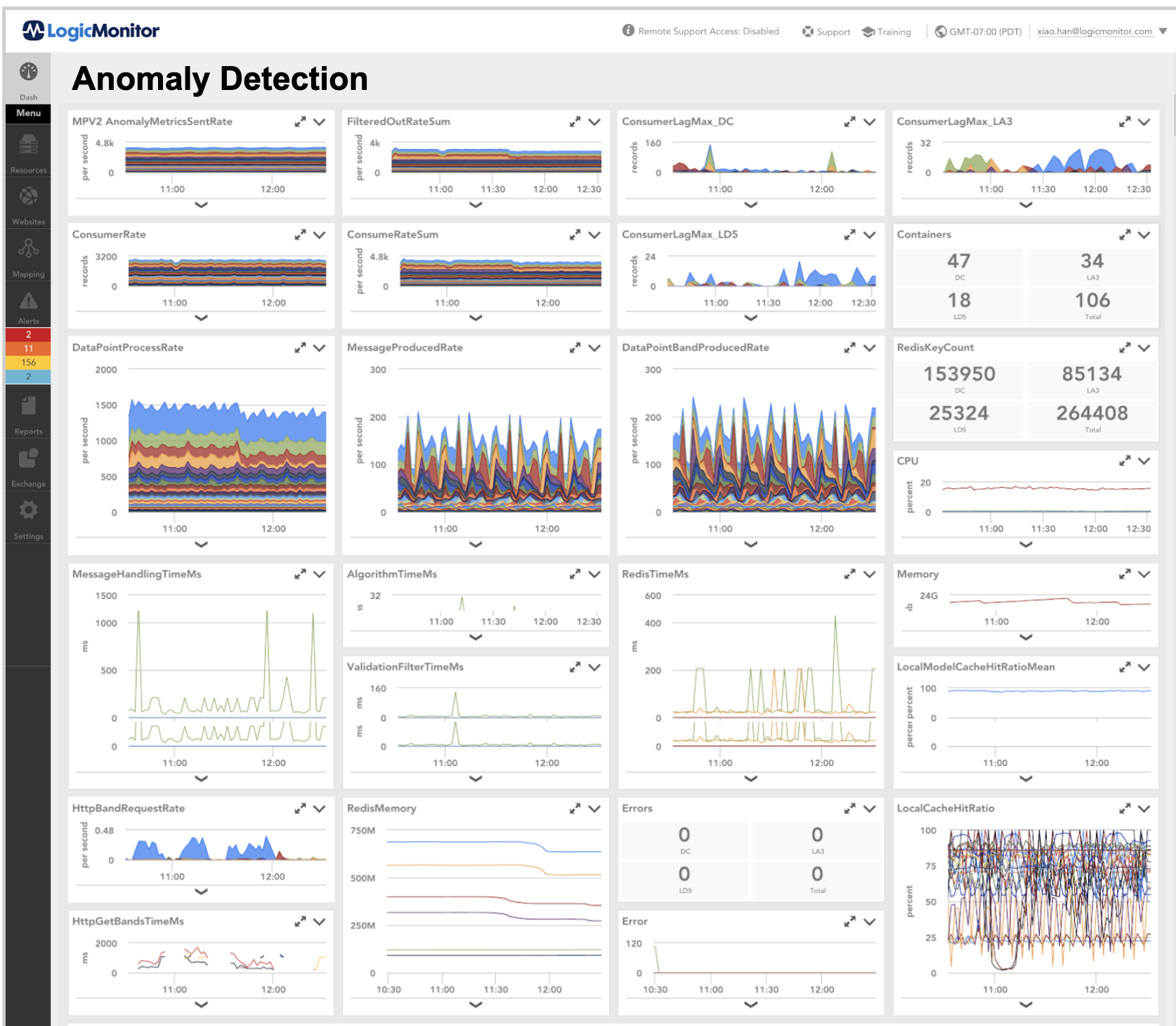
すべてのマイクロサービスはLogicMonitorで監視されています。 これは、モニターダッシュボードの例です。 これは、CPU使用率の変更により、コンテナーレプリカの数が自動的にスケールアップおよびスケールダウンされたことを示しています。
上位5つのKPI
マイクロサービスのKPI監視にはLogicMonitorを使用します。 KPIメトリックには、次のものが含まれますが、これらに限定されません。
- カフカの消費者の遅れ–カフカの生産者と消費者の間にある遅れ
- リクエスト率または消費率–XNUMX秒あたりのネットワークリクエスト数
- レイテンシー–Kafkaに作成されたレコードがコンシューマーによってフェッチされるまでにかかる時間
- エラー率–トピックのエラーが発生したXNUMX秒あたりの平均レコード送信数
- リソース使用量(CPU、メモリ)
異常検出マイクロサービスダッシュボードの例を次に示します。