

LogicMonitorでは、主に大量の時系列データを扱います。 当社のバックエンドインフラストラクチャは、数十億のメトリック、イベント、および構成を毎日処理します。
以前のブログでは、からの移行について説明しました モノリスからマイクロサービスへ。 また、なぜ私たちが選んだのかを説明しました クォークス Javaベースのマイクロサービス用のマイクロサービスフレームワークとして。
このブログでは、以下について説明します。
- QuarkusおよびMicrometerメトリックとは何ですか?
- メトリック処理パイプラインのXNUMXつの主要なKPI
- マイクロメータメトリックの使用方法
- LogicMonitorマイクロサービステクノロジースタック
- 構成の変更をメトリックに関連付ける方法
- 異常を追跡する方法
QuarkusおよびMicrometerメトリックとは何ですか?
クォークス は、OpenJDKHotSpotおよびGraalVM用に調整されたKubernetesネイティブJavaスタックです。 これは、最高のJavaライブラリと標準から作成されています。
ミクロメーター JVMベースのアプリケーション用のメトリックインストルメンテーションライブラリです。 これは、ベンダーやその特定の収集メカニズムにとらわれないJavaAPIに面したコードです。 これは、アプリケーションからのメトリック収集を簡素化し、移植性を最大化するのに役立つように設計されています。
Quarkusは、JVMおよびカスタムメトリック収集のためのMicrometer統合を合理化するための拡張機能を提供します。
// gradle dependency for the Quarkus Micrometer extension
implementation 'io.quarkus:quarkus-micrometer:1.11.0.Final'
// gradle dependency for an in-memory registry designed to operate on a pull model
implementation 'io.micrometer:micrometer-registry-prometheus:1.6.3'メトリック処理パイプラインのXNUMXつの主要なKPIは何ですか?
メトリック処理パイプラインの場合、XNUMXつの主要なKPI(主要業績評価指標)は、処理されたメッセージの数と、複数のマイクロサービスにわたるパイプライン全体のレイテンシーです。
アプリケーションの予想されるワークロードの異常を検出するために、時間の経過とともに処理されるメッセージの数に関心があります。 私たちのワークロードは時間とともに変動しますが、通常は予測可能なパターンに従います。 これにより、予想以上の負荷を検出してそれに応じて対応できるだけでなく、潜在的なデータ収集の問題を事前に検出することもできます。
データ量に加えて、パイプラインのレイテンシーにも関心があります。 このメトリックは、最初の取り込み時から完全に処理されるまでのすべてのメッセージについて測定されます。 このメトリックを使用すると、マイクロサービス固有のメトリックと組み合わせてパイプライン全体の状態を監視でき、Kafkaクラスター間での転送に費やされた時間が含まれます。 さまざまなマイクロサービス。 各メッセージの合計処理時間を監視するため、平均処理時間だけでなく、p50、p95、p999などのさまざまなパーセンタイル値についてレポートおよびアラートを送信できます。 これは、パイプラインに沿ったマイクロサービス内の99つまたは複数のノードが異常である場合を検出するのに役立ちます。 すべてのメッセージの平均処理時間はそれほど変わらない可能性がありますが、高いパーセンタイル(p999、pXNUMX)は増加し、局所的な問題を示します。
マイクロメータは、KPIに加えて、メモリ使用量、CPU使用率、ガベージコレクションなど、通常のアプリケーション監視に使用できるJVMメトリックを公開します。
マイクロメータメトリックの使用方法
Quarkusのコンテキスト内でMicrometerを使用するには、XNUMXつの依存関係が必要です。 ザ・ quarkus-マイクロメートル依存性 コードをインストルメント化するために必要なインターフェースおよびその他のクラスを提供します。 さらに、目的のレジストリへの依存関係も必要です。 複数のレジストリから選択できます。 マイクロメータ-レジストリ-プロメテウス はメモリ内レジストリであり、Quarkusを使用すると、RESTエンドポイントを使用してメトリックを簡単に公開できます。 これらのXNUMXつの依存関係は XNUMXつの拡張子 Quarkus1.11.0.Final以降。
Quarkus Micrometer拡張機能は、メソッド呼び出しのカウントと時間測定に非常に便利なアノテーション(@Countedと@Timed)をサポートします。 ただし、これは単一のマイクロサービス内のメソッドに限定されます。
@Timed(
value = "processMessage",
description = "How long it takes to process a message"
)
public void processMessage(String message) {
// Process the message
}プログラムでタイマーメトリックの値を作成して提供することもできます。 これは、期間を計測したいが、個別の測定値を提供したい場合に役立ちます。 この方法を使用して、マイクロサービスパイプラインのKPIを追跡しています。 取り込みタイムスタンプをKafkaヘッダーとして各メッセージに添付し、パイプライン全体で費やされた時間を追跡できます。
@ApplicationScoped
public class Processor {
private MeterRegistry registry;
private Timer timer;
// Quarkus injects the MeterRegistry
public Processor(MeterRegistry registry) {
this.registry = registry;
timer = Timer.builder("pipelineLatency")
.description("The latency of the whole pipeline.")
.publishPercentiles(0.5, 0.75, 0.95, 0.98, 0.99, 0.999)
.percentilePrecision(3)
.distributionStatisticExpiry(Duration.ofMinutes(5))
.register(registry);
}
public void processMessage(ConsumerRecord<String, String> message) {
/*
Do message processing
*/
// Retrieve the kafka header
Optional.ofNullable(message.headers().lastHeader("pipelineIngestionTimestamp"))
// Get the value of the header
.map(Header::value)
// Read the bytes as String
.map(v -> new String(v, StandardCharsets.UTF_8))
// Parse as long epoch in millisecond
.map(v -> {
try {
return Long.parseLong(v);
} catch (NumberFormatException e) {
// The header can't be parsed as a Long
return null;
}
})
// Calculate the duration between the start and now
// If there is a discrepancy in the clocks the calculated
// duration might be less than 0. Those will be dropped by MicroMeter
.map(t -> System.currentTimeMillis() - t)
.ifPresent(d -> timer.record(d, TimeUnit.MILLISECONDS));
}
}集約されたタイマーメトリックは、https:// quarkusHostname / metricsのRESTエンドポイントを介して取得できます。
# HELP pipelineLatency_seconds The latency of the whole pipeline.
# TYPE pipelineLatency_seconds summary
pipelineLatency_seconds{quantile="0.5",} 0.271055872
pipelineLatency_seconds{quantile="0.75",} 0.386137088
pipelineLatency_seconds{quantile="0.95",} 0.483130368
pipelineLatency_seconds{quantile="0.98",} 0.48915968
pipelineLatency_seconds{quantile="0.99",} 0.494140416
pipelineLatency_seconds{quantile="0.999",} 0.498072576
pipelineLatency_seconds_count 168.0
pipelineLatency_seconds_sum 42.581
# HELP pipelineLatency_seconds_max The latency of the whole pipeline.
# TYPE pipelineLatency_seconds_max gauge
pipelineLatency_seconds_max 0.498次に、コレクターを使用して、これらのメトリックをDataPointとしてLogicMonitorに取り込みます。
LogicMonitorマイクロサービステクノロジースタック
環境内でQuarkusを使用して複数のマイクロサービスを構築したLogicMonitorのメトリックパイプラインは、次のテクノロジースタックにデプロイされています。
- Java 11(corretto、cuzライセンス)
- Kafka(AWS MSKで管理)
- Kubernetes
- Nginx(Kubernetes内の入力コントローラー)
構成の変更をメトリックにどのように関連付けるのですか?
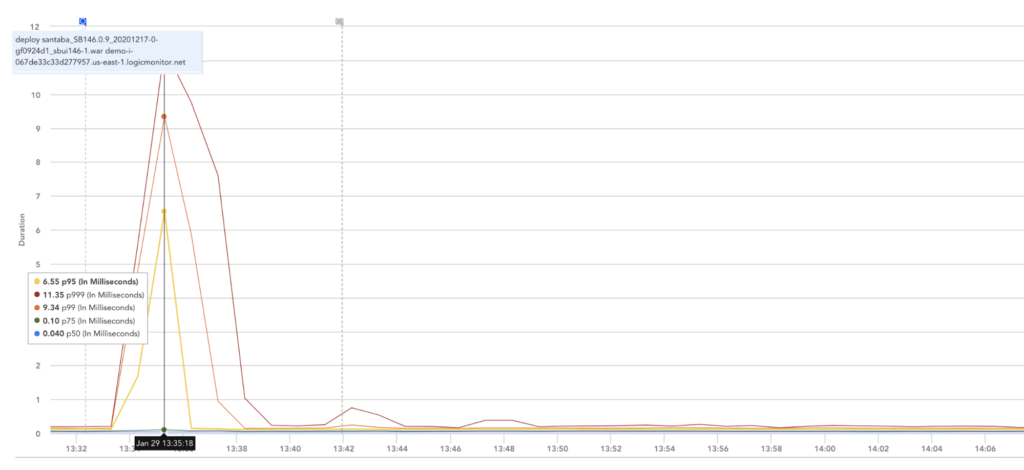
これらのメトリックがLogicMonitorに取り込まれると、グラフとして表示したり、ダッシュボードに統合したりできます。 また、アラート、異常検出に使用することもでき、ops-notesと組み合わせて、インフラストラクチャや構成の変更、およびその他の重要なイベントに関連して視覚化することもできます。
以下は、新しいバージョンの展開に関連する処理時間の増加の例です。 新しいバージョンをデプロイすると、ops-noteが自動的にトリガーされ、グラフやダッシュボードに表示できます。 この例では、この機能により、遅延の増加とサービスの展開の間の相関関係が促進されます。
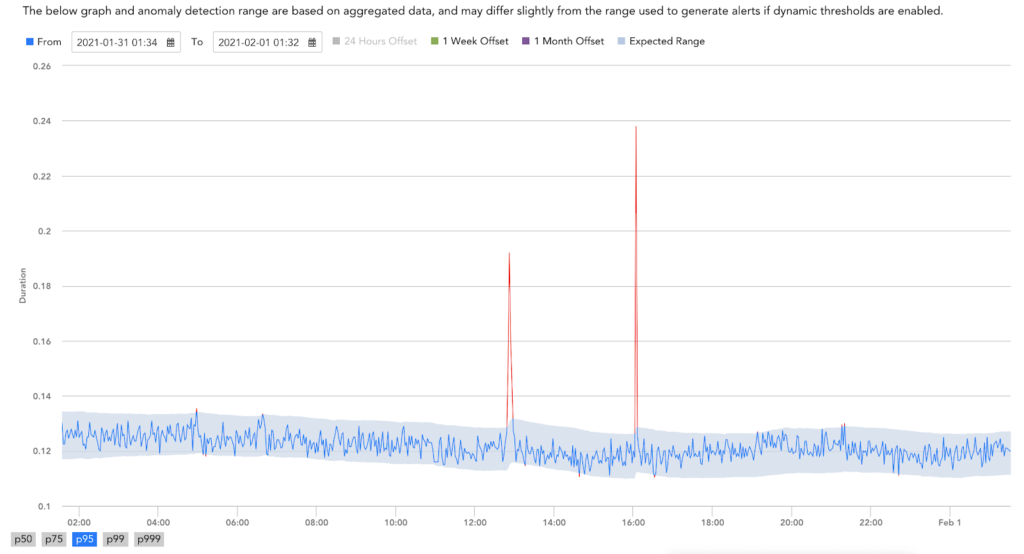
異常を追跡する方法
すべてのマイクロサービスはLogicMonitorで監視されています。 これは、パイプラインレイテンシ95パーセンタイルの異常検出の例です。 LogicMonitorは、通常の動作値を動的に計算し、期待値のバンドを作成します。 その後、値が生成された帯域外になったときにアラートを定義することができます。
上記のように、MicroMeterとQuarkusの統合により、LogicMonitorと組み合わせて、マイクロサービスに可視性を追加するための簡単で簡単かつ迅速な方法が可能になります。 これにより、処理パイプラインがクライアントに最大の価値を提供すると同時に、エンジニアの監視作業を最小限に抑え、コストを削減し、生産性を向上させることができます。

