

今日、モノリシックアプリケーションは、すべての機能がXNUMXつのユニットに配置されているため、処理するには大きすぎるように進化しています。 多くの企業は、それらをマイクロサービスアーキテクチャに分解する必要があります。
LogicMonitorには、いくつかのレガシーモノリシックサービスがあります。 ビジネスが急速に成長するにつれて、スケールアウトはオプションではなかったため、これらのサービスをスケールアップする必要がありました。
最終的に、私たちの最大の問題点は次のようになりました。
- サービスをスケールアップするコストは高かった。
- 新機能には、Javaで最適化されていないML / AIアルゴリズムが必要でした。
- 新しい機能の場合、QA、展開、およびメンテナンスのオーバーヘッドは莫大でした。
- 新しいエンジニアのオンボーディングは長く苦痛でした。
この記事では、MonolithとMicroservicesの両方の利点、Microservice、Kafka Microservice通信からの特定の要件、およびデータを分散して負荷を分散する方法について説明します。
モノリスとマイクロサービス
モノリスアプリケーションは、すべての機能がXNUMXつのユニットに組み込まれているアプリケーションです。 マイクロサービスアプリケーションは、単一のユニットを分解する小さなサービスです。 それらは独立して実行され、連携して動作します。 以下は、MonolithとMicroservicesの両方の利点です。
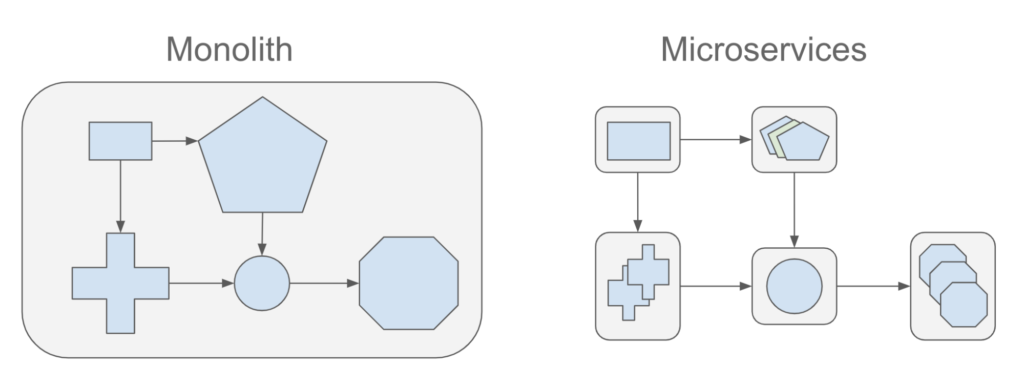
モノリス:
アプリケーションの複雑さが高くなく、かなり静的でなく、エンジニアの数が「少ない」限り、次のようになります。
- デバッグとテストが簡単 –エンドツーエンドのテストをはるかに高速に実行できます。
- 導入が簡単 –展開はXNUMXつだけです。
- 開発が簡単 –通常、すべての知識は少数の主要なエンジニアに存在します。
- 管理が容易 –ロギングとパフォーマンスモニタリングは簡単に設定できます。
マイクロサービス:
マイクロサービスは、スケーラブルなアプリケーションを構築し、複雑なビジネス上の問題を解決する上で多くの利点を提供します。
- 簡単な拡張で –各マイクロサービスには非常に特殊なジョブがあり、他のコンポーネントのジョブとは関係ありません。
- パフォーマンスの最適化 –ホットサービスを分離し、他のアプリケーションとは独立してスケールアップ(イン/アウトまたはアップ/ダウン)できます。
- QAとテストが簡単 –各サービスは、明確に定義された入力と出力を使用して自己テストできます。
- 分離 –分離されたサービスは、さまざまなアプリ(WebクライアントやパブリックAPIなど)の目的に対応するために、再構成および再構成も簡単です。
- さまざまな開発スタック –各サービスは、それ自体に最適な開発スタックを使用して実装できます(たとえば、Python JavaとGoを使用しています)。
- 優れた復元力とフォールトトレランス –分離されたモジュールは、XNUMXつのモジュールのバグがサービス全体をダウンさせるのを防ぎます。
- 導入が簡単 –マイクロサービスの開発と展開の時間ははるかに短くなります。
マイクロサービスの要件
LogicMonitorは、XNUMX日あたり数十億のペイロード(データポイント、ログ、イベント、構成など)を処理します。 高レベルのアーキテクチャは、データ処理パイプラインです。
パイプライン内の各マイクロサービスに対する要件は次のとおりです。
- 各マイクロサービスコンポーネントはステートレスである必要があります(必要に応じて、状態はデータストアに保持されます(Redis、Kafkaなど))。
- 各マイクロサービスコンポーネントは、Xミリ秒でタスクを完了する必要があります
- 各マイクロサービスはk8sコンテナベースであり、動的にスケールアウト/スケールインできます
- エンドツーエンドパイプラインはXミリ秒未満である必要があります
- マイクロサービスのウォームアップ時間はXミリ秒未満である必要があります
- 各マイクロサービスは、X個のCPUコアとY個のGBメモリによって制限されます
- コスト(インフラストラクチャ/ツール)は、ペイロードあたり年間Xドル未満である必要があります
- 各マイクロサービスは生成する必要があります 有用なログとメトリック 監視用
現在、Java、Python、Goでマイクロサービスが実装されています。 各マイクロサービスはKubernetesクラスターにデプロイされ、メトリックに基づいて自動的にスケールアウトするか、KubernetesのHorizontal PodAutoscalerを使用してスケールアウトできます。
Javaの場合、複数のマイクロサービスフレームワークを評価した後、新しいJavaマイクロサービスでQuarkusを使用することにしました。 Quarkusは、Java仮想マシン(JVM)用に調整されたKubernetesネイティブのJavaフレームワークです。
Quarkusを選んだ理由の詳細については、 クォークス対春 ブログ。
データを分散して負荷を分散する方法
LogicMonitorによって監視されるデータポイントを処理および分析するためのマイクロサービスを実装しました。 各マイクロサービスは、受信データに対して特定のタスクを実行します。
いくつかのテクノロジーを評価した後、使用することにしました カフカ マイクロサービス間の通信メカニズムとして。 Kafkaは、ストリーミングメッセージのパブリッシュおよびサブスクライブに使用できる分散ストリーミングメッセージプラットフォームです。 Kafkaは、大量のストリーミングデータに対して、高速でスケーラブルで耐久性のあるメッセージプラットフォームを提供します。
Kafkaトピックを分割する方法
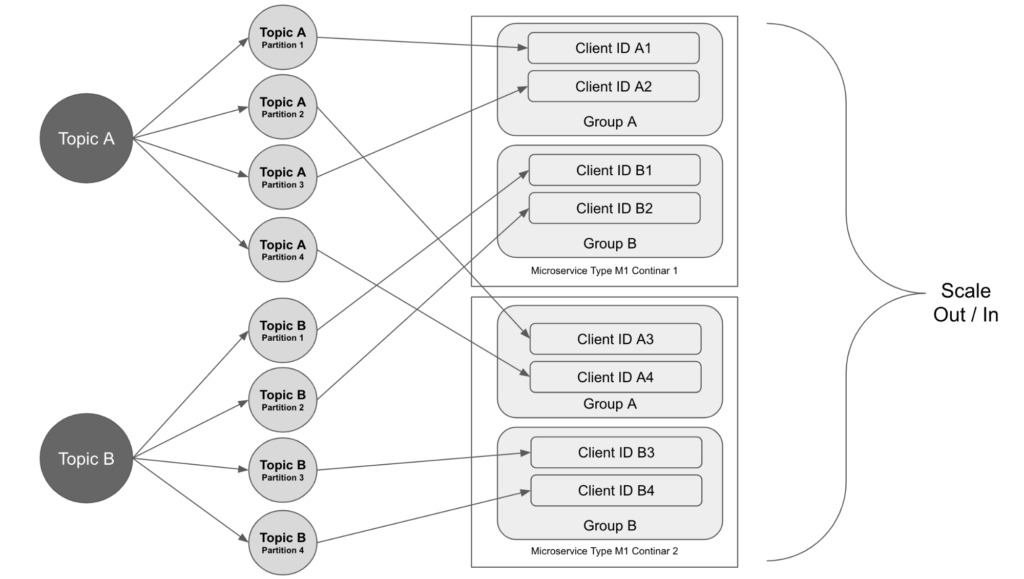
当社のマイクロサービスは、Kafkaトピックを使用して通信します。 各マイクロサービスは、いくつかのKafkaトピックからデータメッセージを取得し、処理結果を他のいくつかのトピックに公開します。
Kafkaの各トピックはパーティションに分割されています。 トピックのデータを消費するマイクロサービスでは、複数のインスタンスが実行されており、それらは同じコンシューマーグループに参加しています。 パーティションは、グループ内のコンシューマーに割り当てられます。 サービスがスケールアウトすると、さらに多くのインスタンスが作成され、コンシューマーグループに参加します。 パーティションの割り当ては、コンシューマー間で再調整されます。 各インスタンスは、作業するXNUMXつ以上のパーティションを取得します。
この場合、パーティションの総数によって、マイクロサービスがスケールアップできるインスタンスの最大数が決まります。 トピックのパーティションを構成するときは、大量のデータを処理するために必要なマイクロサービスのインスタンスの数を考慮する必要があります。
データの配布とバランス調整
マイクロサービスがデータメッセージをKafkaトピックのパーティションに公開する場合、パーティションはランダムに、またはメッセージのキーに基づくパーティショニングアルゴリズムに基づいて決定できます。
同じデバイスからの時系列データメッセージが同じパーティションに順番に到着し、順番に処理されるように、メッセージキーとして内部IDを使用することを選択しました。
複数のパーティションにわたるトピックのデータは、バランスが崩れる場合があります。 私たちの場合、一部のデータメッセージは他のパーティションよりも多くの処理時間を必要とし、一部のパーティションには他のパーティションよりも多くのそのようなメッセージがあります。 これにより、一部のマイクロサービスインスタンスが遅れます。 この問題を解決するために、データメッセージを複雑さに基づいてさまざまなトピックに分け、コンシューマーグループをさまざまに構成しました。 これにより、サービスをより効率的にスケールインおよびスケールアウトできます。
マイクロサービスの状態を維持する場所
一部のマイクロサービスはステートフルであるため、拡張が困難です。 この問題を解決するために、 Redisクラスター 状態を維持します。
Redis Clusterは、複数のRedisノードの分散実装であり、高速なインメモリデータストアを提供します。 これにより、アルゴリズムモデルを高速に保存およびロードでき、必要に応じてスケールアウトできます。
まとめ
モノリスをマイクロサービスに移行することは、場合によっては数年かかることがある旅です。
LogicMonitorでは、XNUMX年前にこの旅を始めました。 投資収益率については議論の余地がありません。 メリットには次のものが含まれますが、これらに限定されません。
- 開発の生産性が向上し、技術的負債が削減されます。
- サービスはより回復力があり、パフォーマンスが向上します。
- 継続的デプロイがより簡単になり、サービスのダウンタイムが発生しません。
- サービスを拡張する方が簡単で効率的です。

