

リアルタイムまたは事後分析でログをふるいにかけて問題を特定するには、数時間かかる場合があります。これは、アラート/ログの干し草の山から針を見つけようとするようなものです。 さらに、トラブルシューティングプロセスを効率的に維持することは、コンテキストの切り替えや、イベントの手動解釈とテクノロジ固有の知識に依存しているため、課題となる可能性があります。 LMログ すべてのログデータとITインフラストラクチャのパフォーマンスメトリックを単一の統合されたステータスベースのプラットフォームに一元化するため、何が起こっているのか、どこで起こっているのか、なぜ起こっているのかを答えることができます。
LogicMonitorテクニカルオペレーションチームがLMログで経験した利点と、今日のより大きなITOpsおよびDevOpsチームが直面しているログの課題に直接適用する方法を理解するために読み続けてください。
LogicMonitorのTechOps
LogicMonitorのTechOpsチームの使命は、顧客にLogicMonitorサービスを提供する、信頼性の高いコンピューティングプラットフォームを構築、拡張、および維持することです。 彼らの仕事はXNUMXつの主要なカテゴリーに分類することができます:
#1-サービスの可用性を向上させることにより、顧客体験を向上させます。
#2-プロセスのスケーリングまたは自動化、アラートの積極的な調整、他の部門からの要求への対応により、同僚の仕事を容易にします。
目標には、LogicMonitorサービスを顧客に確実に提供すること、潜在的または顧客が気付く前に混乱を認識できるようにすること、プロアクティブゾーンとリアクティブゾーンで時間を過ごすこと、技術的負債の蓄積を回避すること、およびLogicMonitorを利用してLMサーバーの信頼性を確保することが含まれます。
LMログを使用したログ分析
ログは、人または実行中のプロセスのいずれかによって、コンピューティングシステムで発生するイベントの記録です。 ログは、何が起こったかを追跡し、問題をトラブルシューティングするのに役立ちます。ログは、アプリケーションまたは時系列メトリックのカバレッジを監視する上で重要な部分です。
ログの確認は困難で時間がかかり、多くの場合、ログを理解するには専門知識が必要です。 LMログを挿入します。 LM Logsは、強力な特許取得済みのアルゴリズムを利用して、独自の検索クエリ言語を学習することなく、取り込み時にログ、データ、およびイベントのすべての要素を自動的に分析します。 LM Logsは、ログ内の異常をプロアクティブに識別し、これらのイベントを自動的にエスカレーションすることにより、一元化されたログ集約アプローチをさらに一歩進めます。 さらに、ログインメトリックデータは真に統合されています。つまり、ログデータは、パフォーマンスメトリックダッシュボードまたはグラフからコンテキスト内ですぐに分析できます。
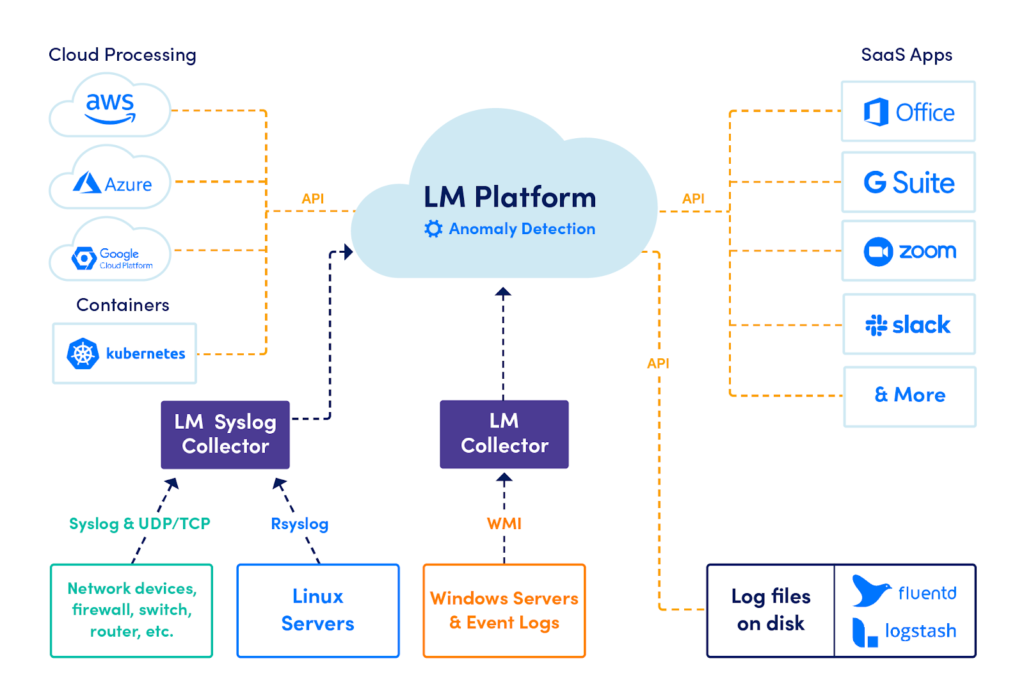
LMログがITOpsおよびDevOpsチームにどのように価値を付加するか
LogicMonitorは、すべてのOpsチームがログにアクセスでき、痛みを伴わないようにする必要があると考えています。したがって、LM Logsは、これまでに作成された最初のソリューションです。 IT運用チームとDevOpsチームを念頭に置いて構築。 LM TechOpsチームがLMログの統合からどのように利益を得たかの例を詳しく見ていきましょう。これにより、最終的にMTTRが減少し、根本原因分析の決定に必要な時間が短縮され、パフォーマンスまたは可用性に影響を与えることに焦点が当てられます。何が正常か異常かを解読することなく、イベントをすぐにログに記録します。
#1-Kafkaブローカーが停止したときのハードウェアの問題の解決
チームはまだ機能しているサーバーに遭遇しましたが、Kafkaブローカーはリーダーシップを失い、データを適切に複製していませんでした。 LM Logsが登場する前は、Kafka自体のアプリケーションログは問題の原因を特定するのに役に立たず、問題が何であるかを正確に把握しようと複数の人が何時間も費やしていました。 LMログの後、チームは別のサーバーで同じ問題に関するアラートを受け取りました。 今回、彼らは、組織の知識からではなく、アラートとともにログメッセージを表示するLMログから問題を即座に発見しました。 イベントのタイムラインを取り巻く異常なログメッセージと一緒にメトリックベースのアラートを設定することで、状況が明確になりました。
#2-TSDBの問題の発見とRCA時間の短縮
マルチテナントTSDBサーバーがKafkaからのメッセージの消費を停止しました。 このサーバーは、80を超えるさまざまな顧客にサービスを提供しました。 通常、このような状況を診断するには、アプリケーションサーバーのログに精通した誰かによる高度なログ集計クエリが必要になります。 LMログが作成される前は、根本的な原因が明らかになるかどうかを調査するために、この問題に数時間または数日かかる場合がありました。 LMログの後で、根本原因分析プロセスを91人の顧客まで追跡することができました。 わずか6.2分の間に、0000145万のログ行からXNUMXの異常が検出されました。これは、この期間中のログの.XNUMX%のみが問題に関連していたことを意味します。 ありがとう、LMログ。
#3-干し草の山から針を見つけてMTTRを下げる
運用チームは、顧客が容量の制約に関連するパフォーマンスの問題を経験したときに、問題を事前に特定できなければなりません。 この場合、オンコールエンジニアは、応答時間が低下したことを示すメトリックベースのアラートを受信しました。 場合によっては、問題を明らかにするために実際のログを読み取る必要があり、LMログの前は、800,000以上のメッセージをスクロールすることでこれを実行できませんでした。 LMログの後、アラートを処理すると、オンコールエンジニアは関連するログの異常をすばやく確認できました。 ログの異常により、短期的に解決するには手動による介入が必要なバグが明らかになりましたが、将来この問題を防ぐためのフォローアップアクションを作成するために必要なデータも提供されました。 この場合、ログの異常は、パフォーマンスの問題が発見された04分間の合計ログ量の.90%に相当します。
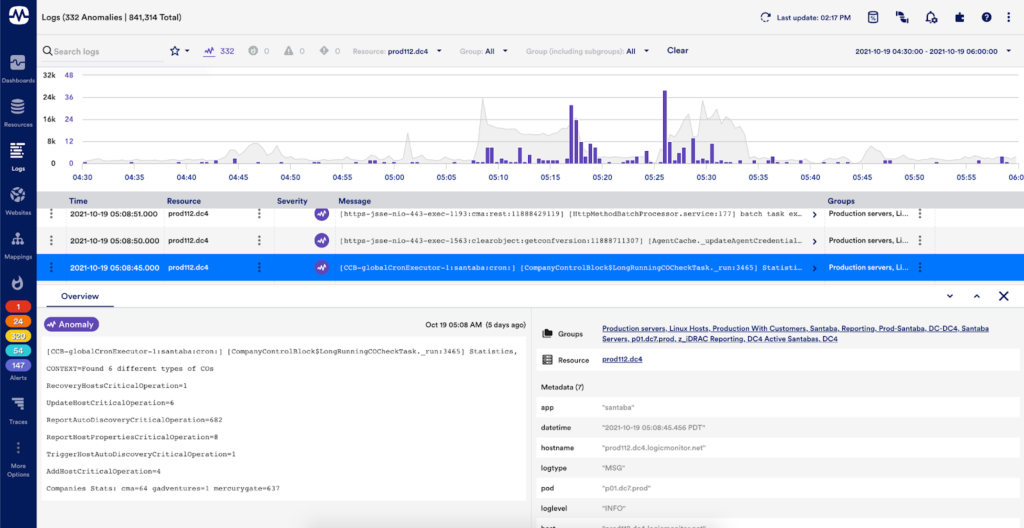
全体として、LM Logsは、すべてのログデータとITインフラストラクチャのパフォーマンスメトリックを単一の統合されたステータスベースのプラットフォームに一元化します。 強力なアルゴリズムを利用してログの異常を自動的に検出して表面化し、労働集約的な分析を排除します。 LMログは、トラブルシューティングと根本原因の分析時間を大幅に短縮し、インシデントウォールームのシナリオを回避し、原因が何であるかを理解するだけでなく、問題を解決するために何を修正する必要があるかを理解するのに役立ちます 良いのために。
LMログが、チームがトラブルシューティングを減らし、ITワークフローを合理化し、制御を強化してリスクを軽減するのにどのように役立つかについて詳しくは、 このオンデマンドウェビナーをご覧ください.